


飞桨星河社区月度报告(2026年2月)
百度大脑
·

世界模型统一框架:突破任务特定知识注入的局限性
Micropaper
·



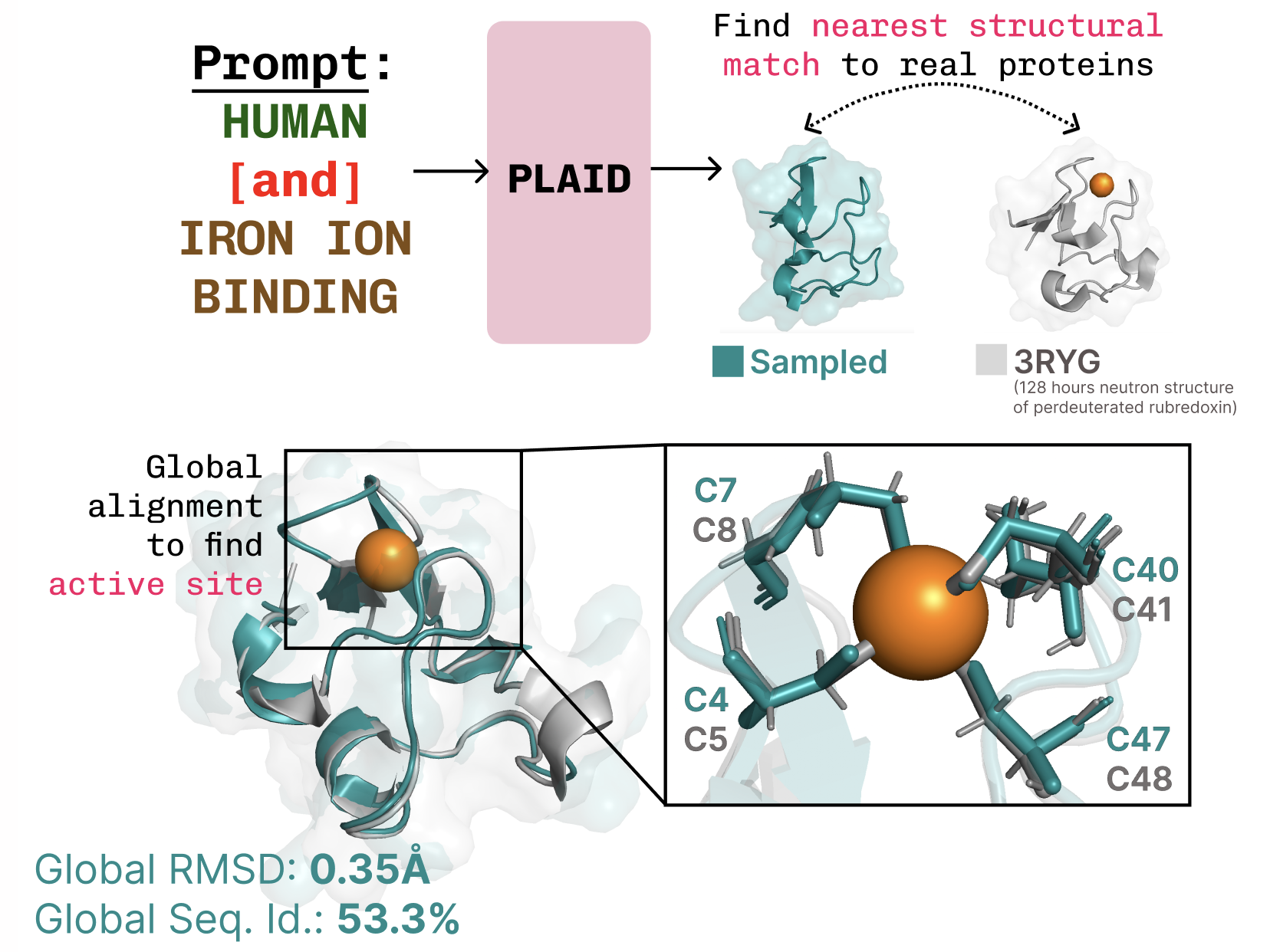
利用潜在扩散重新利用蛋白质折叠模型进行生成
The Berkeley Artificial Intelligence Research Blog
·

