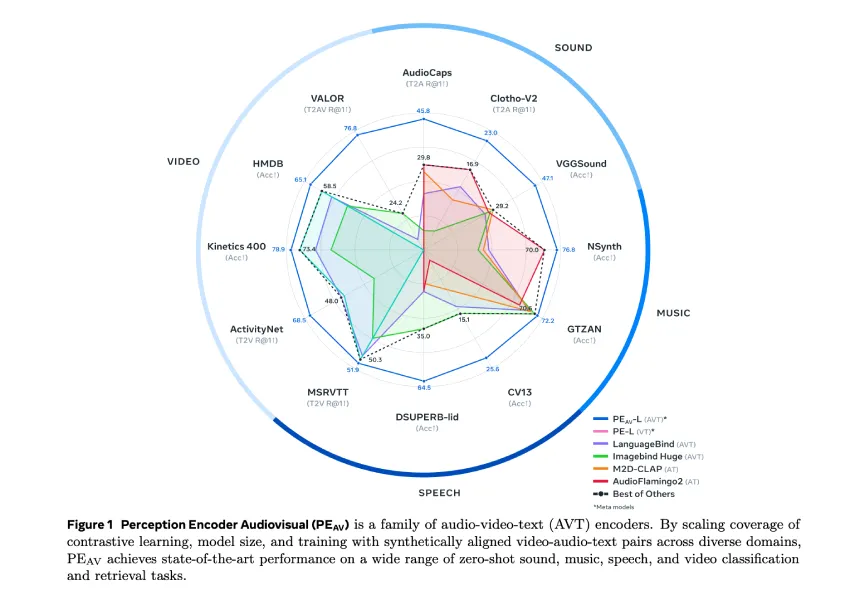
Meta推出了感知编码器视听模型(PE-AV),该模型通过对1亿个带字幕的音视频对进行训练,实现音频、视频和文本的对齐表示。PE-AV在多个基准测试中表现优异,支持跨模态检索和理解,并结合两阶段数据引擎生成合成字幕,提高了多模态监督的效率。
该研究提出了一种新颖的知识传递网络,用于跨模态翻译和情感预测。实验证明该方法相较于基线方法实现了显著改进,并在多模态监督方面取得了相当的结果。
完成下面两步后,将自动完成登录并继续当前操作。