
Meta AI开源感知编码器视听(PE-AV):为SAM音频和多模态检索提供支持的视听编码器
内容提要
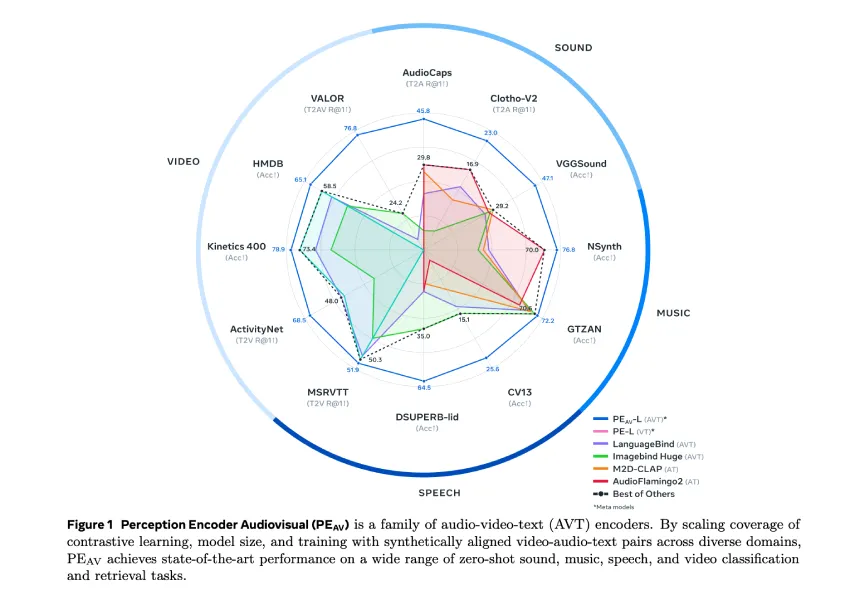
Meta推出了感知编码器视听模型(PE-AV),该模型通过对1亿个带字幕的音视频对进行训练,实现音频、视频和文本的对齐表示。PE-AV在多个基准测试中表现优异,支持跨模态检索和理解,并结合两阶段数据引擎生成合成字幕,提高了多模态监督的效率。
关键要点
-
Meta推出了感知编码器视听模型(PE-AV),用于音频和视频的联合理解。
-
PE-AV通过对1亿个带字幕的音视频对进行训练,实现音频、视频和文本的对齐表示。
-
该模型在多个基准测试中表现优异,支持跨模态检索和理解。
-
PE-AV架构包括帧编码器、视频编码器、音频编码器、音视频融合编码器及文本编码器。
-
音频路径使用DAC VAE编解码器,将原始波形转换为离散音频令牌。
-
两阶段数据引擎生成高质量的合成字幕,第一阶段使用弱音频字幕模型,第二阶段与感知语言模型配对优化字幕。
-
PE-AV在多个音频和视频基准测试中取得了最先进的性能,提升了检索和分类的准确率。
-
PE A-Frame是用于声音事件定位的音频文本嵌入模型,能够精确定位音频中的事件。
-
PE-AV和PE A-Frame是Meta感知模型堆栈的一部分,结合了视觉和语言模型用于多模态生成和推理。
-
PE-AV通过对比学习在广泛的音频和视频基准测试中树立了新的技术水平。
延伸解读
PE-AV的技术优势
PE-AV模型通过对1亿个音视频对进行训练,展示了在音频、视频和文本对齐表示方面的显著优势。这种大规模的对比学习方法使得模型在多个基准测试中取得了最先进的性能,尤其是在零样本检索和分类任务中,表现出色。
多模态检索的应用前景
PE-AV的设计使其能够支持多种模态的检索,包括从文本检索视频或音频。这种灵活性为多模态应用提供了广泛的可能性,尤其是在内容创作、教育和信息检索等领域,能够显著提升用户体验和效率。
合成字幕生成的创新
PE-AV结合了两阶段的数据引擎,能够为未标注的视频生成高质量的合成字幕。这一创新不仅提高了字幕生成的效率,还为大规模多模态监督提供了新的解决方案,减少了对人工标注的依赖。
与现有模型的比较
与其他音频文本模型如CLAP和Audio Flamingo相比,PE-AV在多个基准测试中表现更为优异。这表明PE-AV在技术上具有更高的潜力,尤其是在处理复杂音视频内容时,能够提供更准确的检索和分类结果。
延伸问答
PE-AV模型的主要功能是什么?
PE-AV模型用于音频和视频的联合理解,支持跨模态检索和理解。
PE-AV是如何训练的?
PE-AV通过对1亿个带字幕的音视频对进行大规模对比训练,实现音频、视频和文本的对齐表示。
PE-AV在基准测试中的表现如何?
PE-AV在多个音频和视频基准测试中取得了最先进的性能,提升了检索和分类的准确率。
PE-AV的架构包含哪些组件?
PE-AV架构包括帧编码器、视频编码器、音频编码器、音视频融合编码器及文本编码器。
PE-AV如何生成合成字幕?
PE-AV使用两阶段数据引擎生成合成字幕,第一阶段使用弱音频字幕模型,第二阶段与感知语言模型配对优化字幕。
PE A-Frame模型的用途是什么?
PE A-Frame用于声音事件定位,能够精确定位音频中的事件。
