

如何修复Next.js中的“检测到慢文件系统”
DEV Community
·
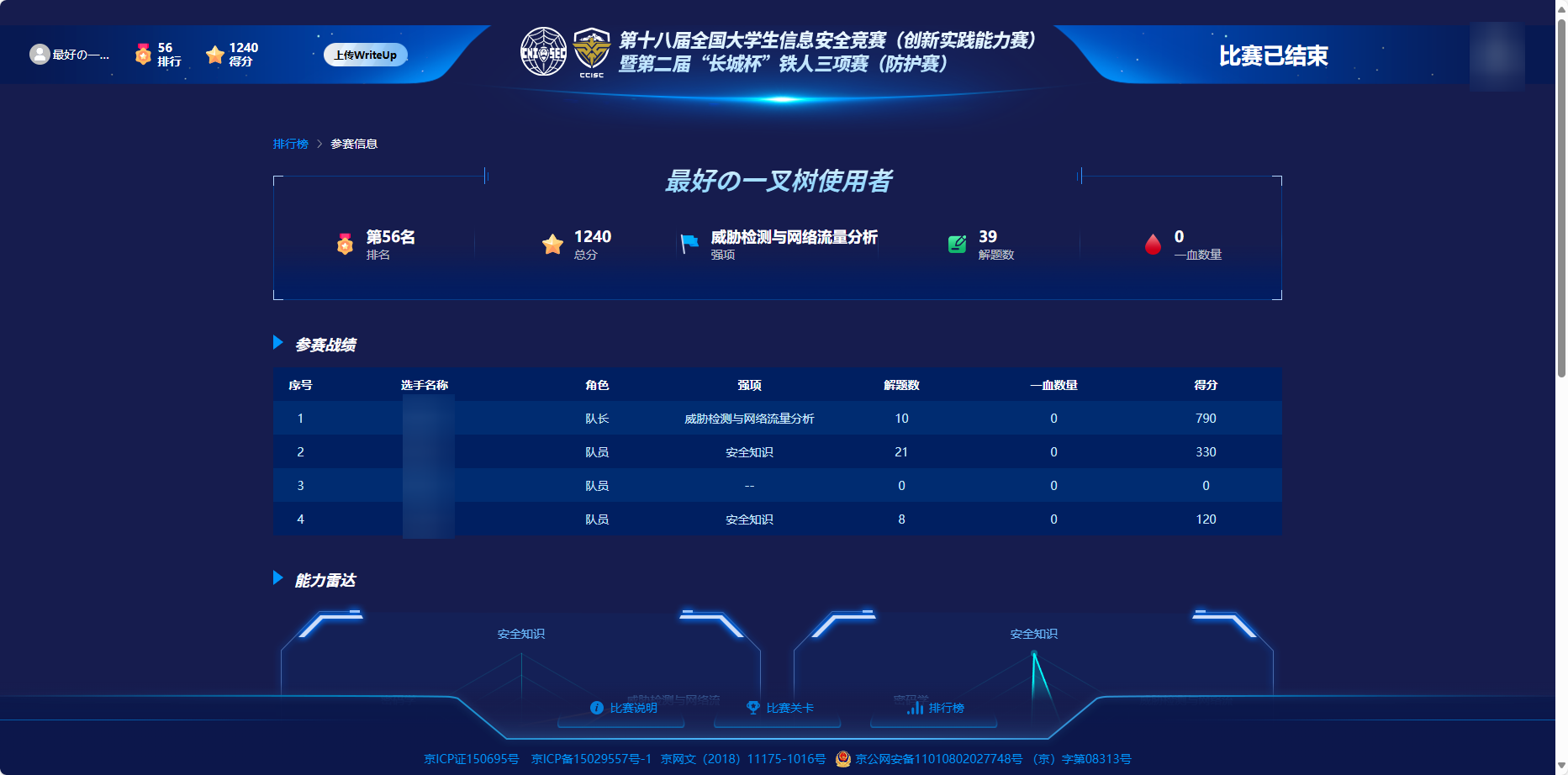
2024 CISCN x 长城杯铁人三项 初赛Writeup
GamerNoTitle
·

通过提示操控破解大型语言模型的新攻击向量
DEV Community
·
多样本越狱 [译]
宝玉的分享
·
