
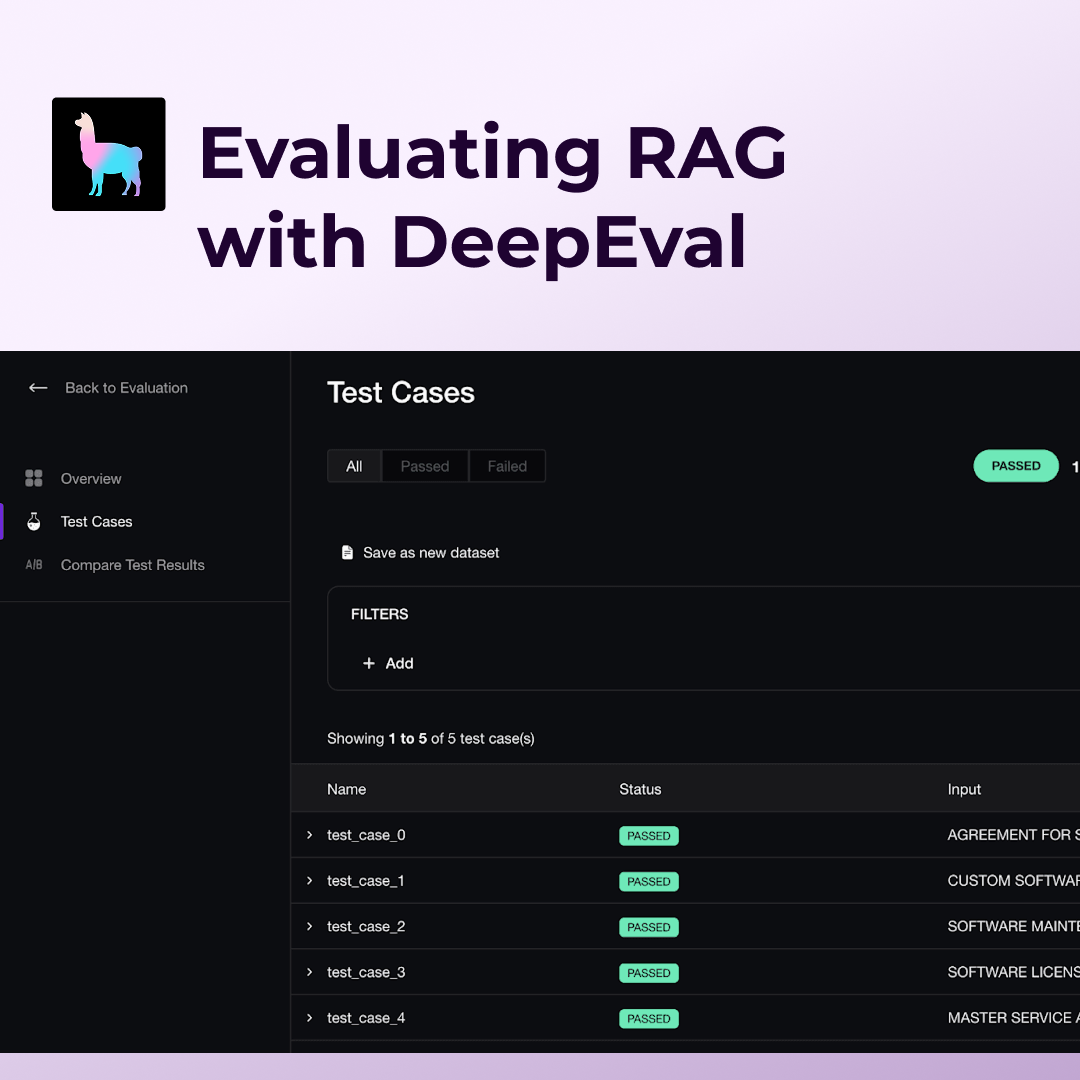
使用DeepEval和LlamaIndex评估RAG
Blog on LlamaIndex
·
关于宽广与短程头部姿态估计的表征和方法学
BriefGPT - AI 论文速递
·
宁愿是护士也不是医生 -- 对比解释的调查研究
BriefGPT - AI 论文速递
·
均衡取舍:工业物联网网络入侵检测的联邦迁移学习
BriefGPT - AI 论文速递
·
