

2026年最佳目标检测模型
The JetBrains Blog
·

如何评估视频会议SDK的性能?
实时互动网
·

如何评估聊天SDK性能?一套可操作的评估框架
实时互动网
·

哪款教育直播SDK更稳定、延迟更低?关键指标的拆解与对比方法
实时互动网
·
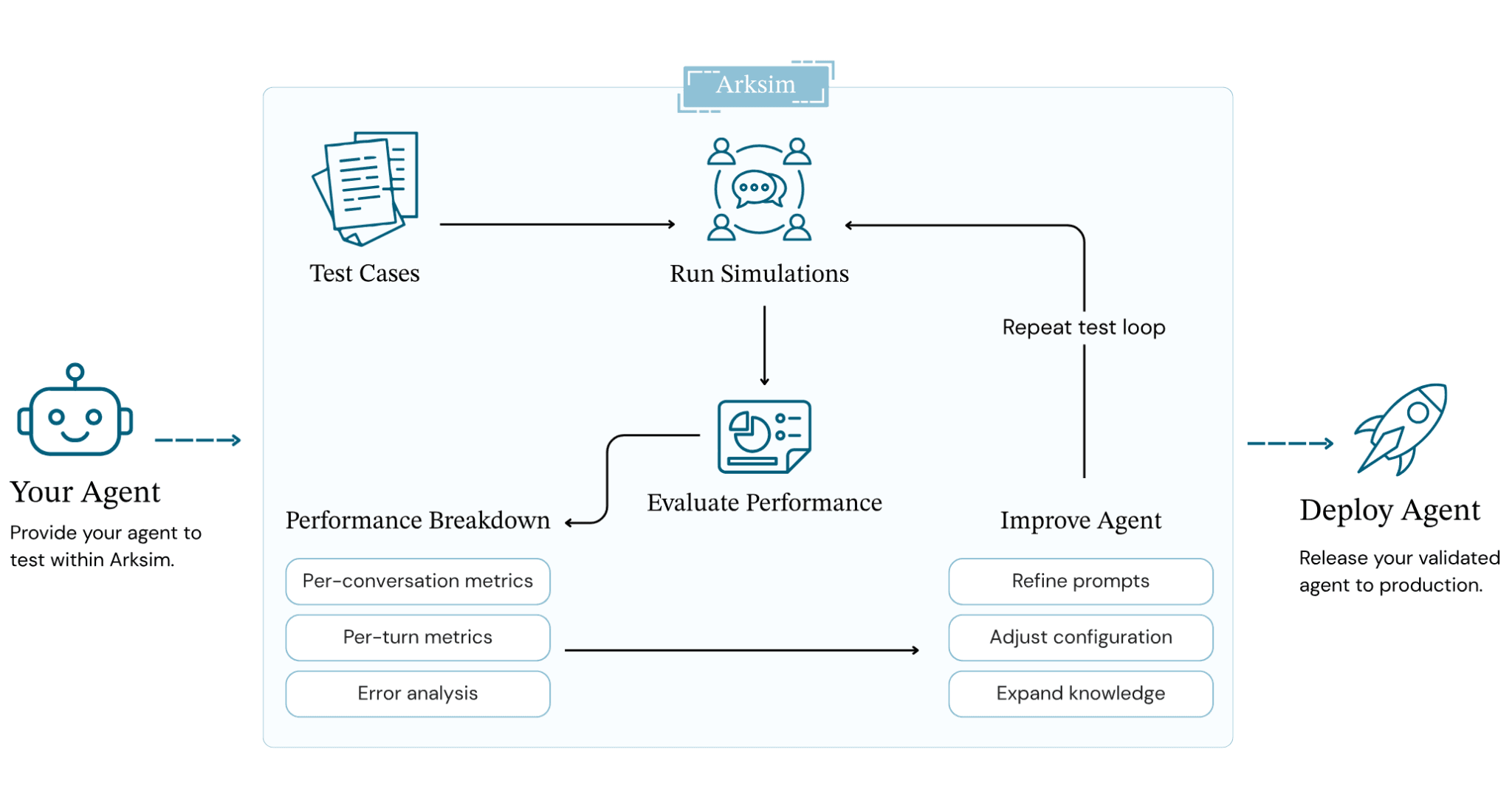
Dify x Arklex:使用开源工具ArkSim测试Dify AI代理
Dify AI
·

元脑企智EPAI平台助力企业智能体上线前量化评估
全球TMT-美通国际
·

MySQL性能:OpenSSL-3.5.5评估
Planet MySQL
·


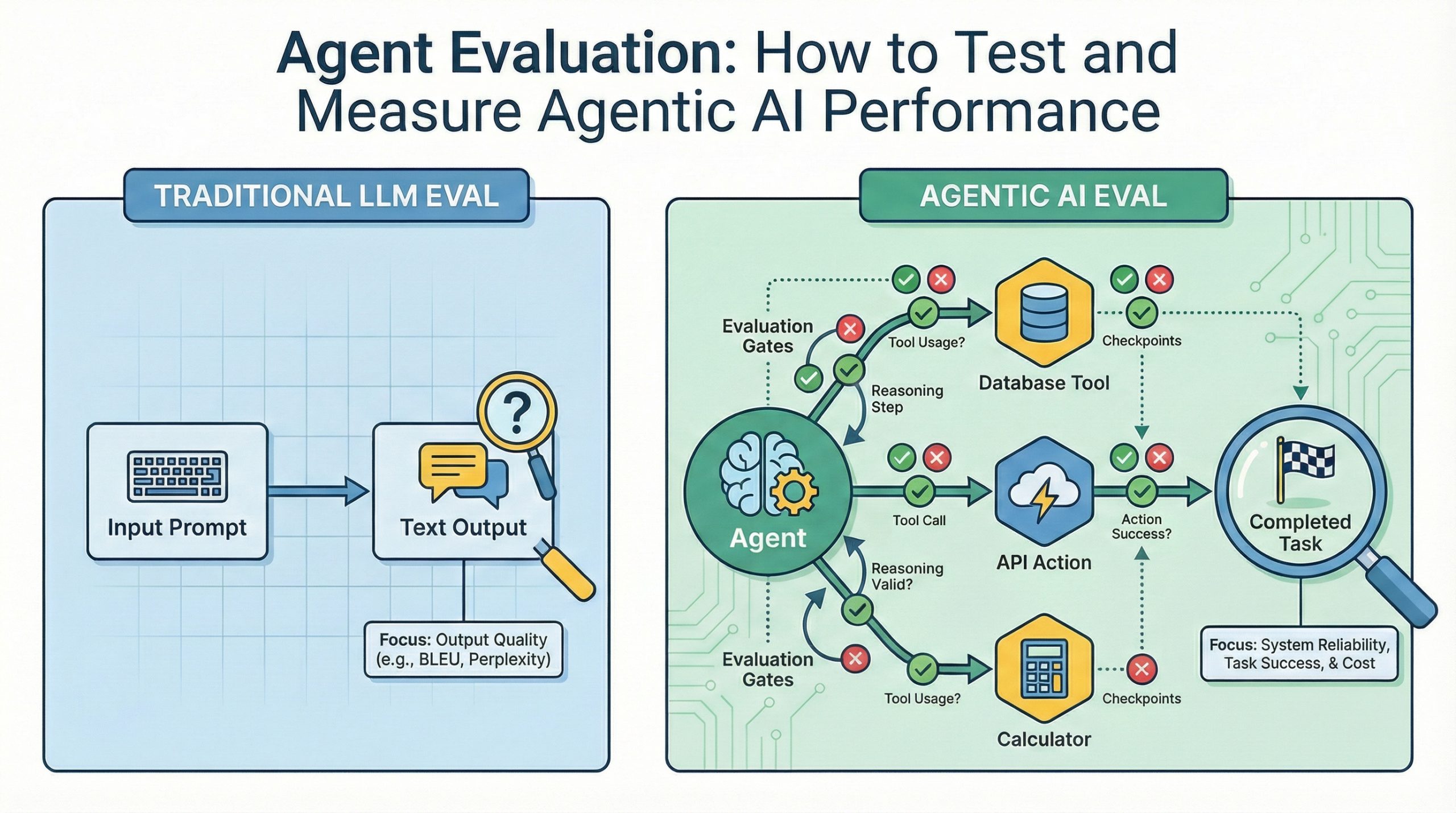
代理评估:如何测试和衡量代理人工智能的性能
MachineLearningMastery.com
·

Various Types of Panels for Linux Servers
Est's Blog
·

第717期:单元测试性能、光标、递归匹配及更多(2026年1月13日)
PyCoder’s Weekly
·

MANZANO:一个简单且可扩展的统一多模态模型,采用混合视觉标记器
Apple Machine Learning Research
·
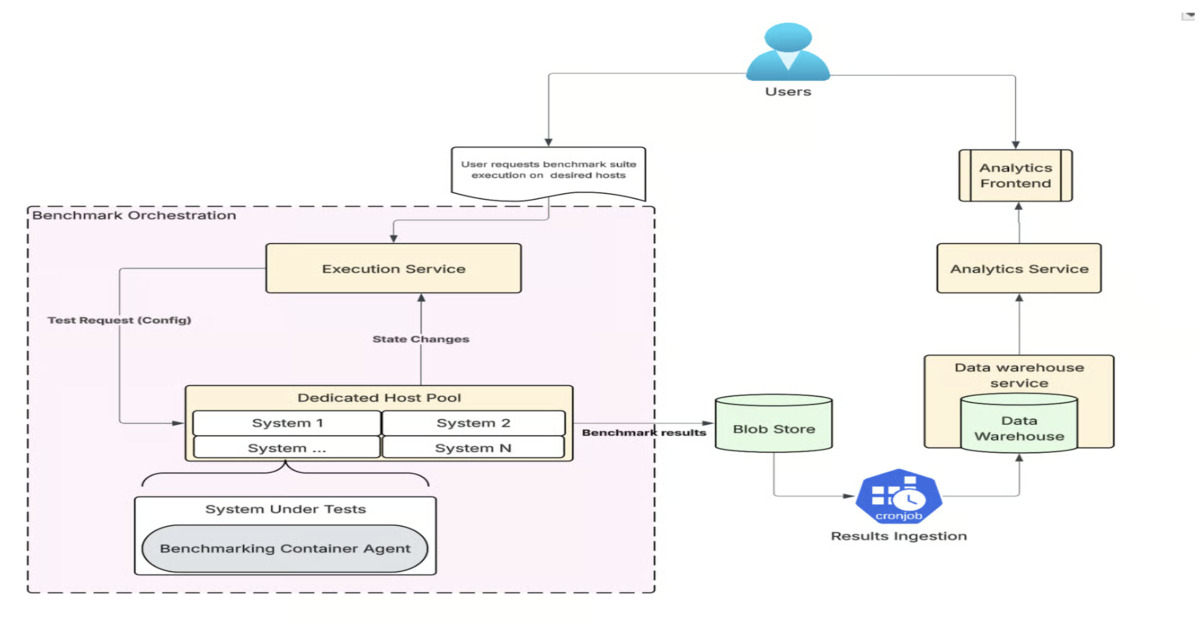
超越应用层的基准测试:Uber如何评估基础设施变更和云SKU
InfoQ
·

EncQA:基于视觉编码的图表视觉语言模型基准评估
Apple Machine Learning Research
·
