
代理评估:如何测试和衡量代理人工智能的性能
内容提要
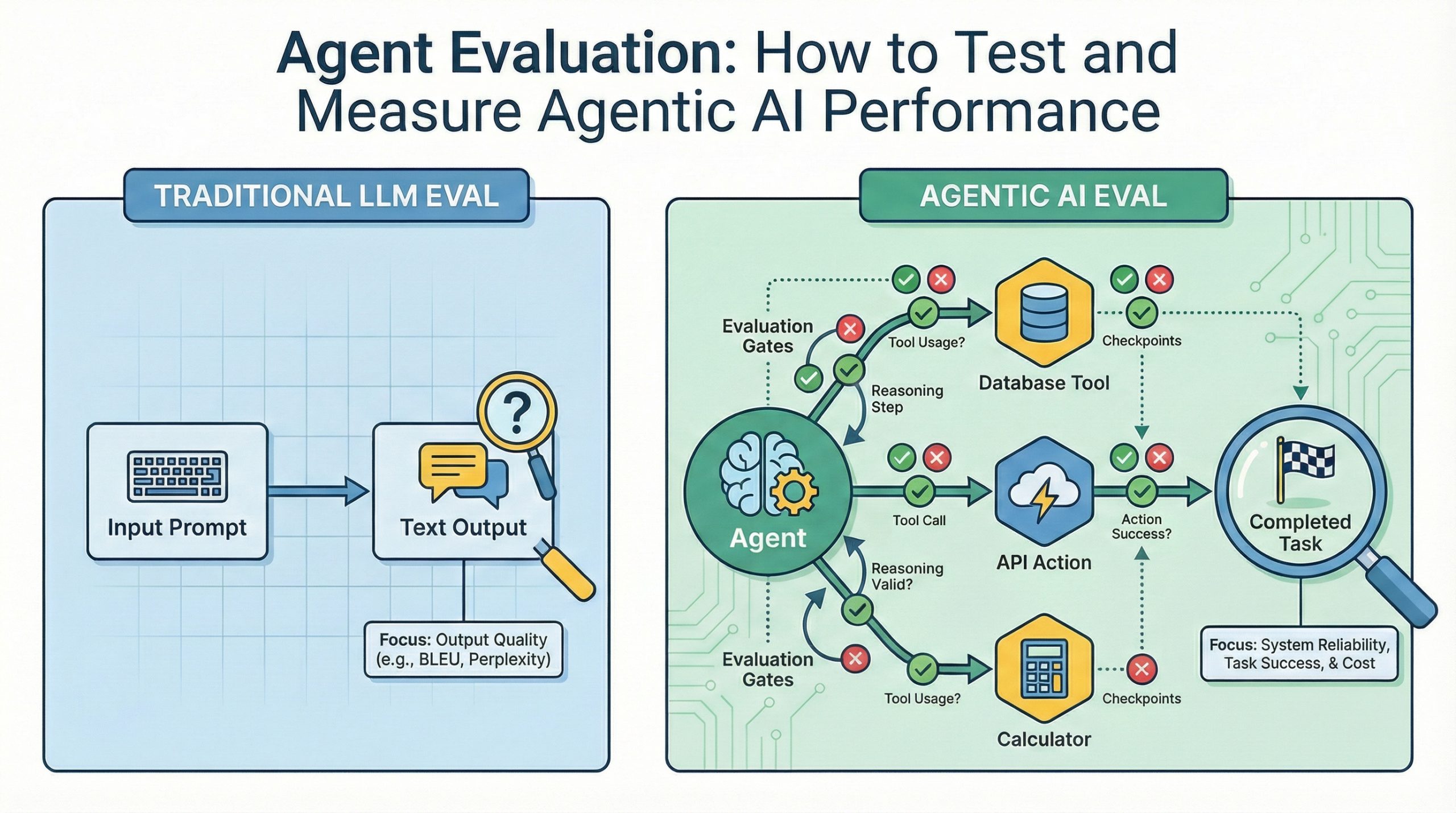
本文探讨了评估代理人工智能系统性能的方法,强调与传统语言模型评估的区别。评估框架包括任务成功、工具使用质量、推理一致性和成本效益四个维度。有效评估需建立黄金数据集,并结合自动化、人工和混合评估方法,以确保代理在实际应用中的可靠性。
关键要点
-
评估代理人工智能系统的性能与传统语言模型评估有根本区别。
-
代理评估框架包括任务成功、工具使用质量、推理一致性和成本效益四个维度。
-
有效评估需要建立黄金数据集,并结合自动化、人工和混合评估方法。
-
任务成功衡量代理是否完成了指定目标,定义需明确。
-
工具使用质量评估代理是否在适当时机调用了正确的工具。
-
推理一致性评估代理的决策过程是否逻辑合理。
-
成本效益权衡量成功任务的成本与所提供价值之间的关系。
-
评估方法分为自动化、人工和混合三种,选择应基于具体约束。
-
建立有效的评估管道需要从黄金数据集开始,确保评估标准与业务目标一致。
-
常见评估陷阱包括使用不反映生产复杂性的合成数据、评估标准偏离业务目标和测试覆盖不足。
延伸解读
代理评估的独特性
代理人工智能的评估与传统语言模型评估有根本区别。传统评估侧重于文本质量,而代理评估则关注任务成功、工具使用质量、推理一致性和成本效益。这种转变强调了代理在实际应用中的可靠性,确保其能够在复杂环境中有效工作。
评估方法的选择
评估代理的方式有自动化、人工和混合三种。选择合适的方法取决于具体的业务需求和约束条件。高频低风险的任务适合自动化评估,而高风险复杂任务则需要人工审核。混合方法能够在保证效率的同时,确保关键决策的质量。
建立黄金数据集的重要性
有效的代理评估依赖于黄金数据集的建立。这个数据集应包含真实的任务示例及其理想输出,帮助评估系统准确衡量代理的表现。创建黄金数据集需要对生产日志进行深入分析,以确保覆盖各种复杂情况和边缘案例。
延伸问答
代理人工智能的评估与传统语言模型评估有什么区别?
代理人工智能的评估关注任务完成、工具使用、推理一致性和成本效益,而传统语言模型评估主要关注文本质量指标,如连贯性和准确性。
如何衡量代理人工智能的任务成功率?
任务成功率通过评估代理是否完成指定目标来衡量,通常需要明确的定义和量化标准。
评估代理人工智能时,工具使用质量如何评估?
工具使用质量评估代理是否在适当时机调用了正确的工具,主要关注调用的相关性、准确性和效率。
建立有效的代理评估管道需要哪些步骤?
建立有效的评估管道需要从创建黄金数据集开始,明确成功标准,并选择合适的评估方法。
代理评估中常见的陷阱有哪些?
常见的评估陷阱包括使用不反映生产复杂性的合成数据、评估标准偏离业务目标和测试覆盖不足。
什么是黄金数据集,它在代理评估中有什么作用?
黄金数据集是一个包含理想输入和期望输出的示例集合,用于作为评估代理性能的基准。
