

FlowEval:基于参考的生成用户界面评估
Apple Machine Learning Research
·

如何在亚马逊云科技上构建企业级智能体
亚马逊AWS官方博客
·

使用RAGAs和G-Eval测试智能体的实践指南
MachineLearningMastery.com
·
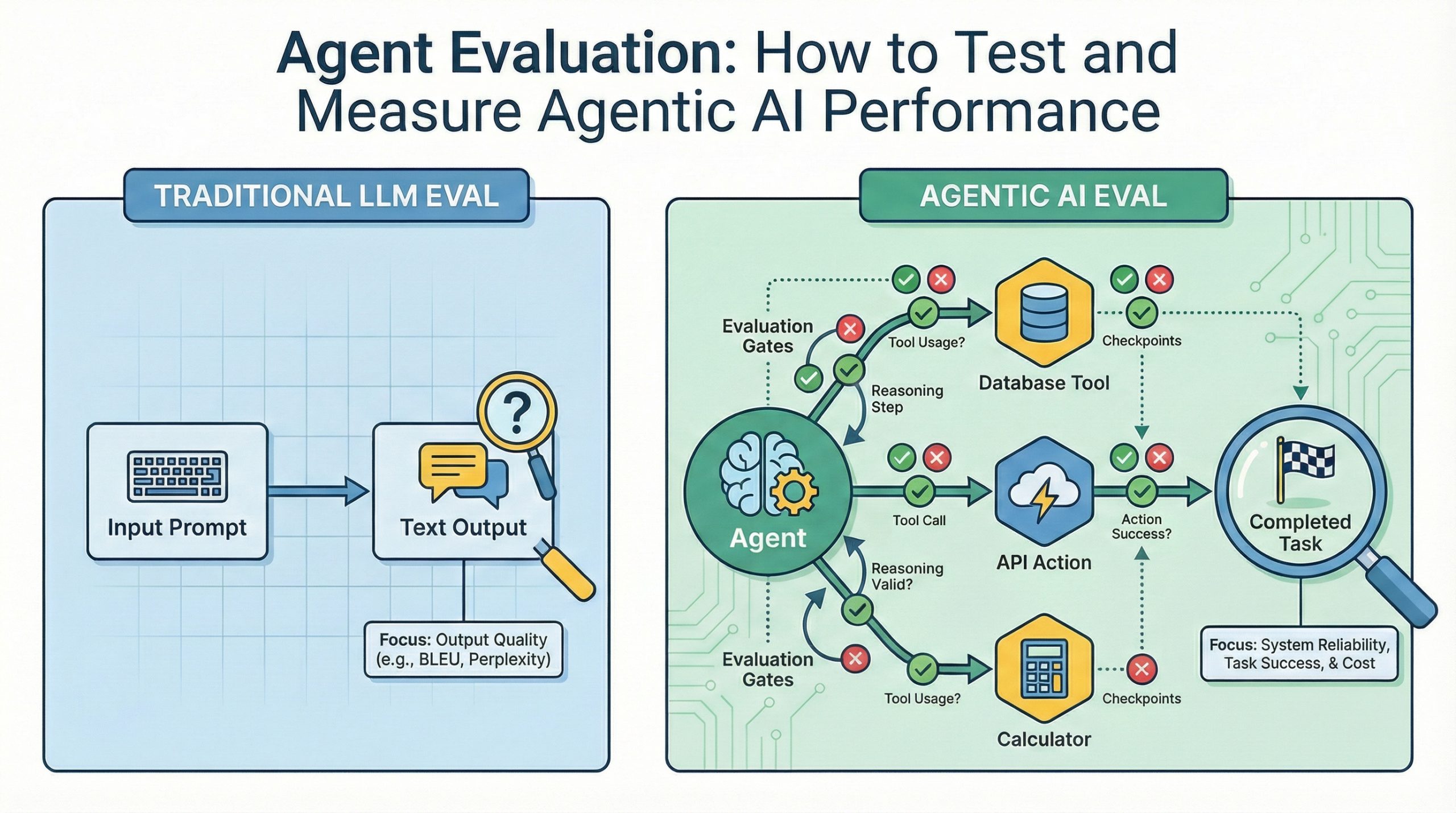
代理评估:如何测试和衡量代理人工智能的性能
MachineLearningMastery.com
·


LLM 评测利器:一站式自动化评估框架 | 开源日报 No.647
开源服务指南
·

工程团队中AI实施的复杂现实
The New Stack
·
Xbox上的Halo如何通过Saga模式扩展到超过1000万玩家
ByteByteGo Newsletter
·

数据准备评估:您的数据是否为人工智能成功做好准备?
DEV Community
·

