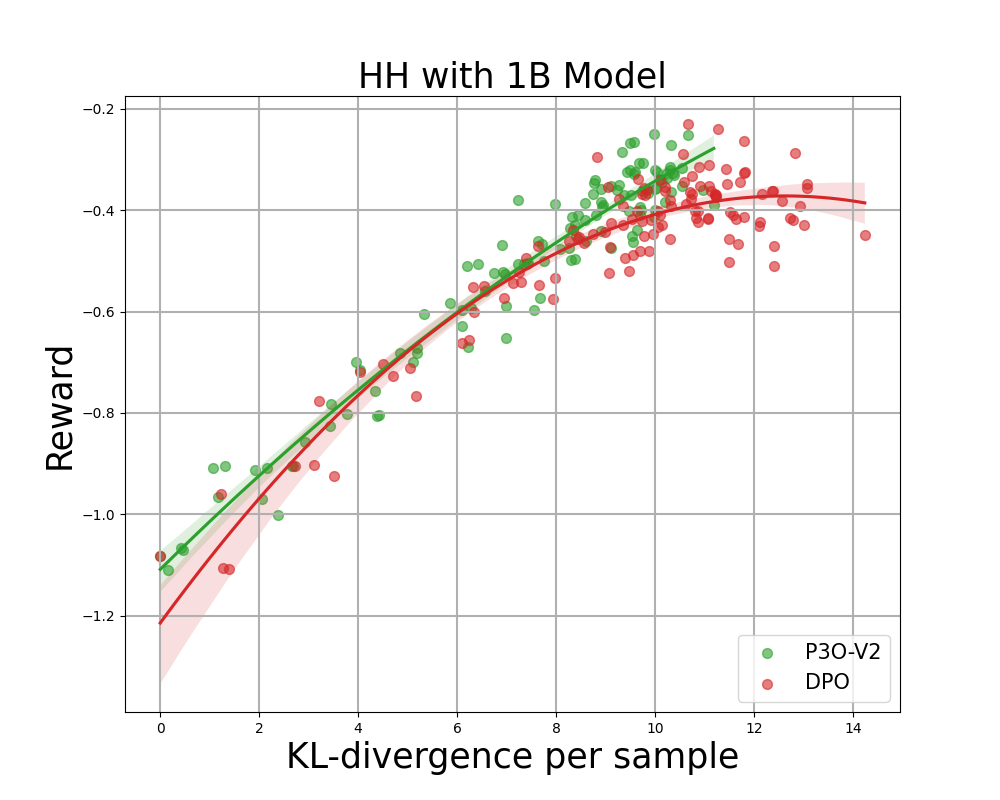
本文探讨了强化学习与人类反馈(RLHF)中奖励学习与强化学习微调之间的矛盾,提出了一种新方法——成对近端策略优化(P3O)。P3O通过比较反馈统一奖励建模和微调过程,在生成任务中表现优于传统方法,更好地与人类偏好对齐,提升生成质量。
完成下面两步后,将自动完成登录并继续当前操作。