
重新思考PPO在强化学习与人类反馈中的角色
原文英文,约1700词,阅读约需7分钟。
📝
内容提要
本文探讨了强化学习与人类反馈(RLHF)中奖励学习与强化学习微调之间的矛盾,提出了一种新方法——成对近端策略优化(P3O)。P3O通过比较反馈统一奖励建模和微调过程,在生成任务中表现优于传统方法,更好地与人类偏好对齐,提升生成质量。
🎯
关键要点
-
在强化学习与人类反馈(RLHF)中,奖励学习阶段使用比较形式的人类偏好,而强化学习微调阶段则优化单一的非比较奖励,二者之间存在矛盾。
-
成对近端策略优化(P3O)通过比较反馈统一奖励建模和微调过程,解决了这一矛盾,能够直接基于成对响应进行更新。
-
P3O方法在生成任务中表现优于传统方法,更好地与人类偏好对齐,提升生成质量。
-
P3O通过引入成对策略梯度,利用奖励差异而非绝对奖励,避免了奖励平移带来的问题。
-
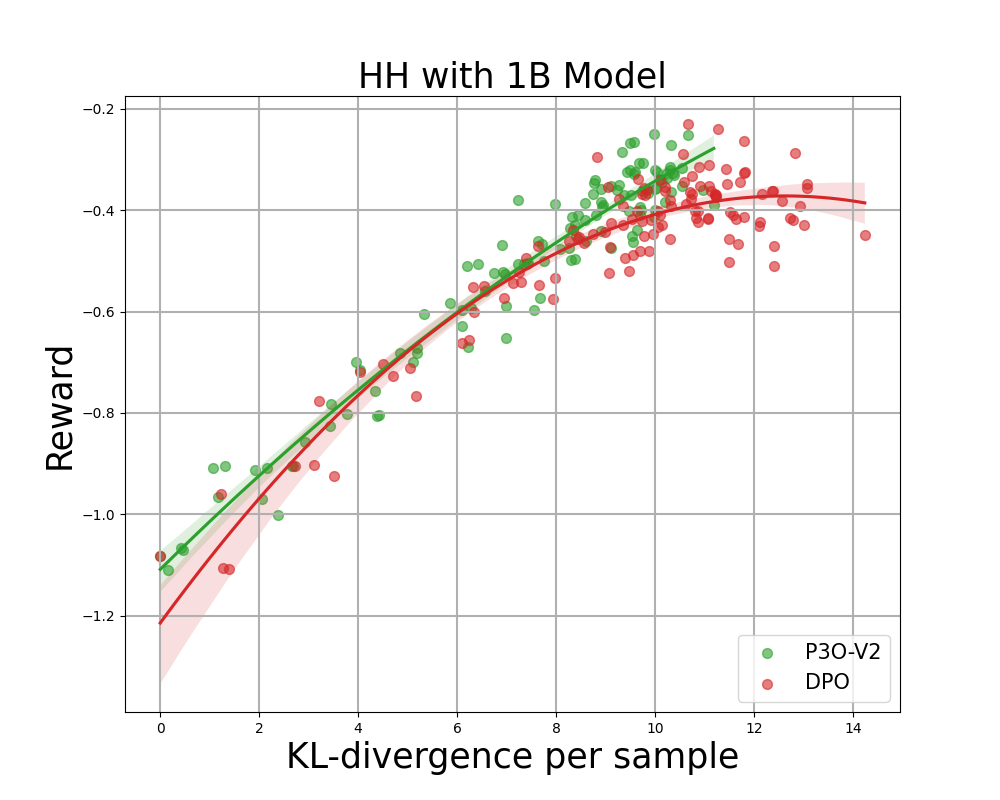
在评估中,P3O在KL-奖励边界和GPT-4的胜率方面均优于其他方法,显示出更好的与人类偏好的对齐能力。
❓
延伸问答
P3O方法如何解决强化学习与人类反馈之间的矛盾?
P3O通过比较反馈统一奖励建模和微调过程,允许直接基于成对响应进行更新,从而解决了奖励学习阶段与强化学习微调阶段之间的矛盾。
P3O在生成任务中的表现如何?
P3O在生成任务中表现优于传统方法,更好地与人类偏好对齐,提升生成质量。
P3O与传统PPO方法相比有哪些优势?
P3O在KL-奖励边界和GPT-4的胜率方面均优于PPO,显示出更好的与人类偏好的对齐能力。
P3O是如何利用奖励差异而非绝对奖励的?
P3O通过引入成对策略梯度,利用奖励差异来避免奖励平移带来的问题,从而实现更有效的学习。
在评估中,P3O的表现如何?
在评估中,P3O在KL-奖励边界和GPT-4的胜率方面均表现优异,显示出其在与人类偏好对齐方面的优势。
P3O的实现过程中使用了哪些技术?
P3O使用了重要性采样和剪切技术,以提高性能并避免过大的梯度更新。
🏷️
