本文探讨了通过自我发明谓词和赋分策略来改善逻辑代理的可解释性和奖励学习效率。提出的基于能量的框架和反事实推理方法在机器人操作任务中表现优异,显著提升了样本效率和决策解释能力。
本文介绍了一种基于强化学习的库存管理系统,旨在优化供应链的计算需求和奖励框架。通过GPU并行化和状态动态规划,该系统实现了新的控制策略,并探讨了未来的研究方向,包括离线奖励学习、知识图谱在推荐系统中的应用,以及逆强化学习的算法改进,以提升样本效率和决策支持。
本文提出了一种基于策略的奖励学习(RLP)无监督框架,旨在通过策略样本优化奖励模型,以提升模型对齐人类偏好和价值的性能。研究还介绍了逆强化学习的监督微调方法、RRHF新范式、主动学习的RLHF方法及线性对齐算法,均在不同场景下显示出显著的性能提升。实验结果表明,这些新方法在训练稳定性和模型质量上优于传统算法。
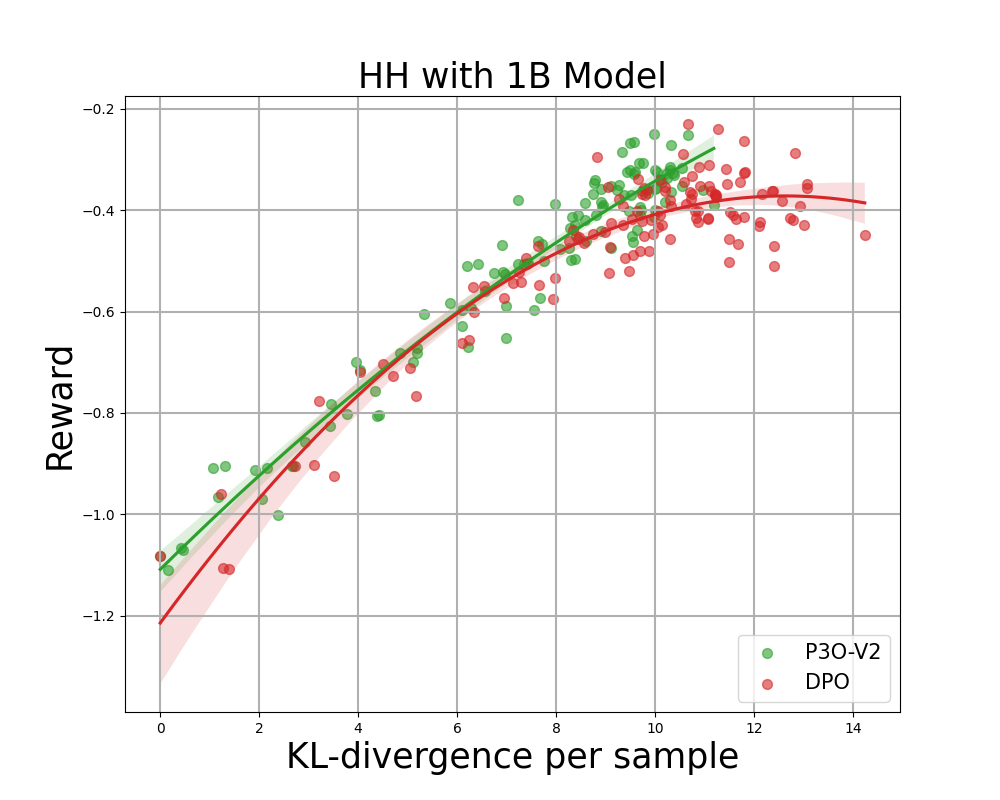
本文探讨了强化学习与人类反馈(RLHF)中奖励学习与强化学习微调之间的矛盾,提出了一种新方法——成对近端策略优化(P3O)。P3O通过比较反馈统一奖励建模和微调过程,在生成任务中表现优于传统方法,更好地与人类偏好对齐,提升生成质量。
该文介绍了一种新的奖励学习模块,可以通过生成模型生成内在奖励信号,提高模块在环境中的动力学建模能力,并为模仿代理提供了模仿者的内在意图和更好的探索能力。该模型在多个 Atari 游戏中的表现优于现有的 IRL 方法,即使只有一次演示,性能也是演示的 5 倍。
完成下面两步后,将自动完成登录并继续当前操作。