

人工智能论文评审:使用非平衡热力学的深度无监督学习
freeCodeCamp.org
·
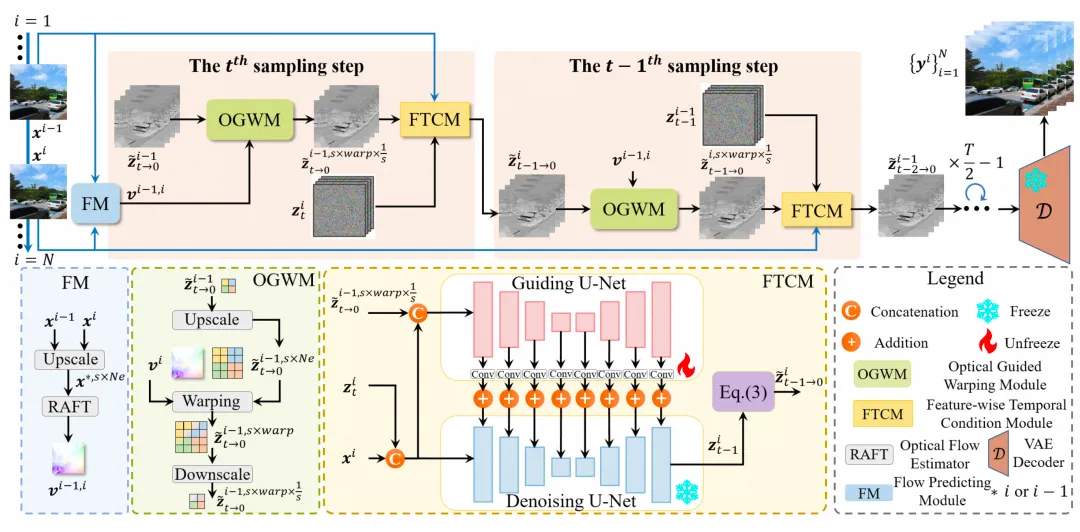
DDIM之父宋佳铭,宣布离职
量子位
·
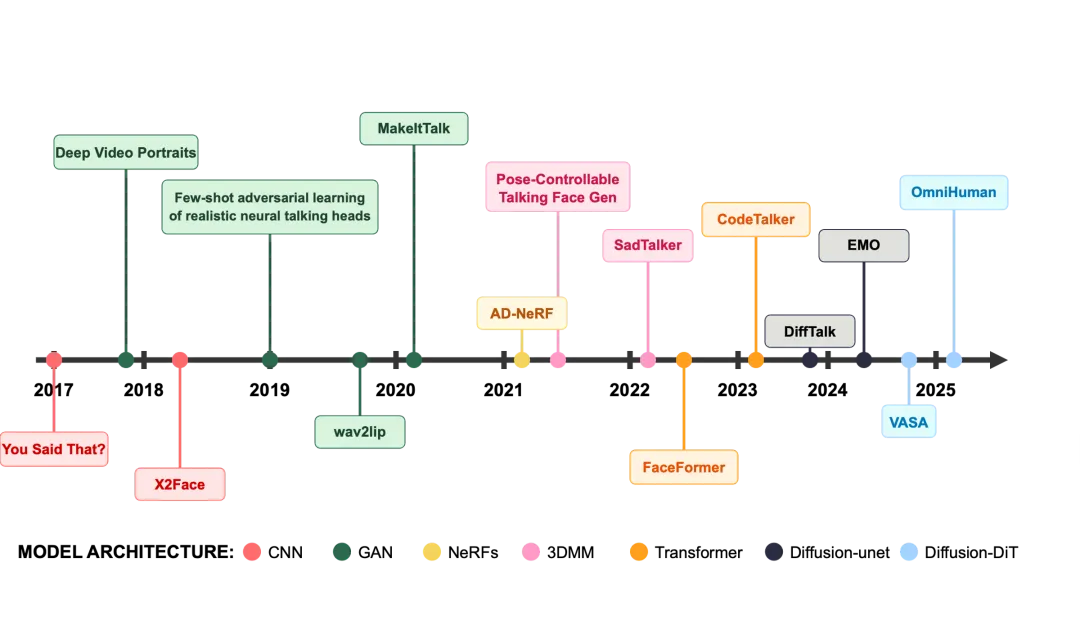
从”对口型”到”数字人” 音频驱动虚拟人合成技术全景解析
实时互动网
·
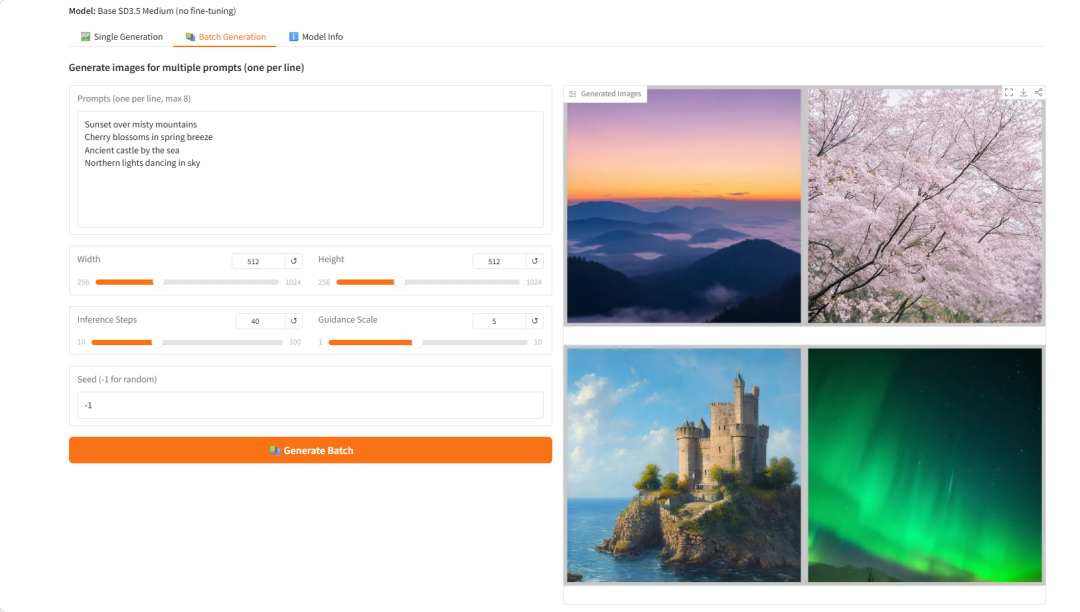
在线教程丨低门槛部署英伟达最新Physical AI模型,覆盖人形机器人/人体运动生成/扩散模型微调等
HyperAI超神经
·
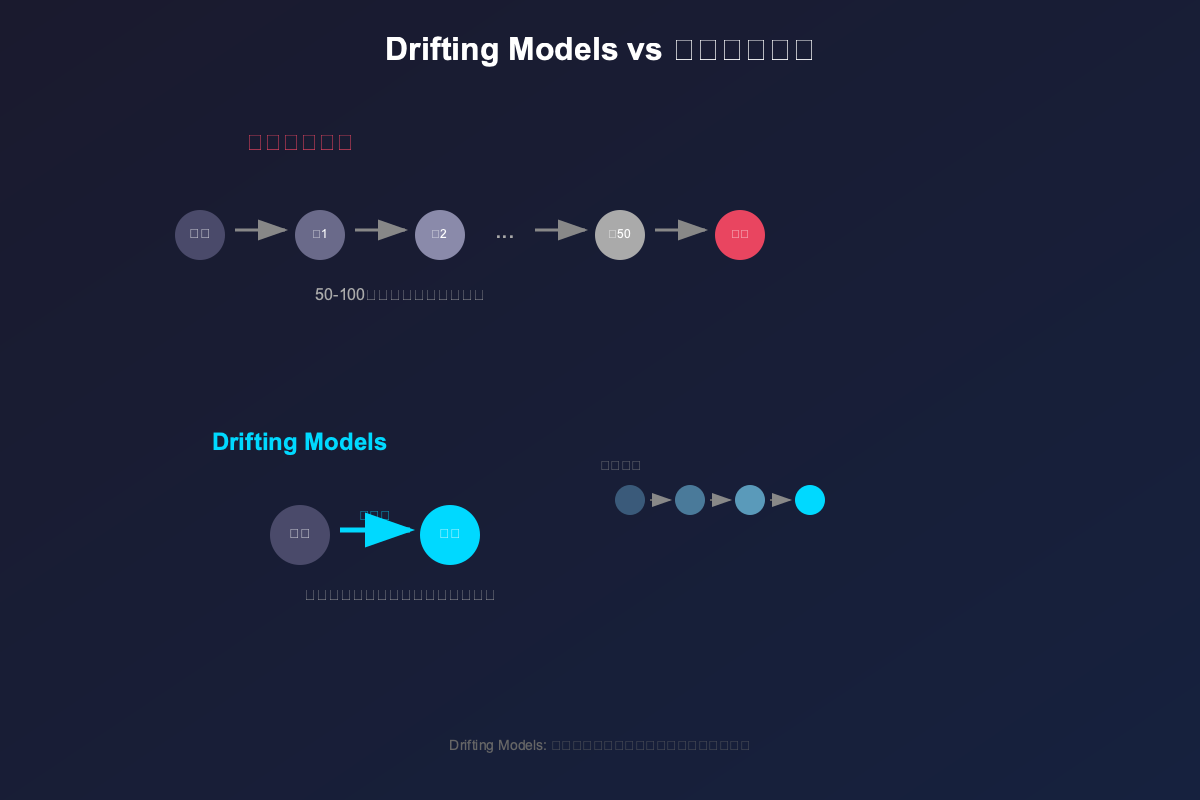
何恺明团队再出大招:Drifting Models 挑战扩散模型,单步生成高质量图像
Micropaper
·
Inception表示其扩散语言模型比Claude、ChatGPT和Gemini快10倍
The New Stack
·


速度提升,能力却暴跌?扩散模型做智能体的残酷真相
机器之心
·
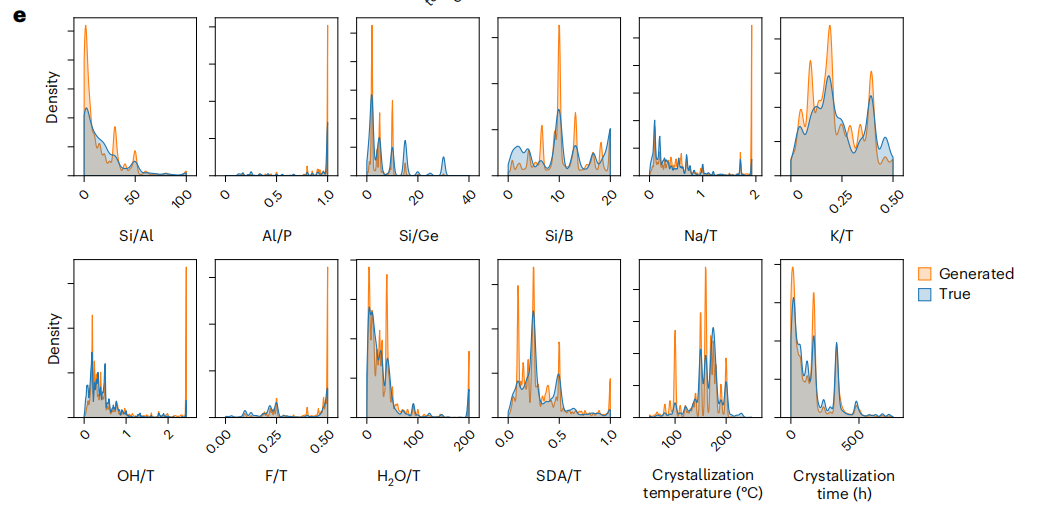
基于超2万条配方,MIT等采用扩散模型规划材料合成,成功制备硅铝比高达19的新型沸石材料
HyperAI超神经
·
