
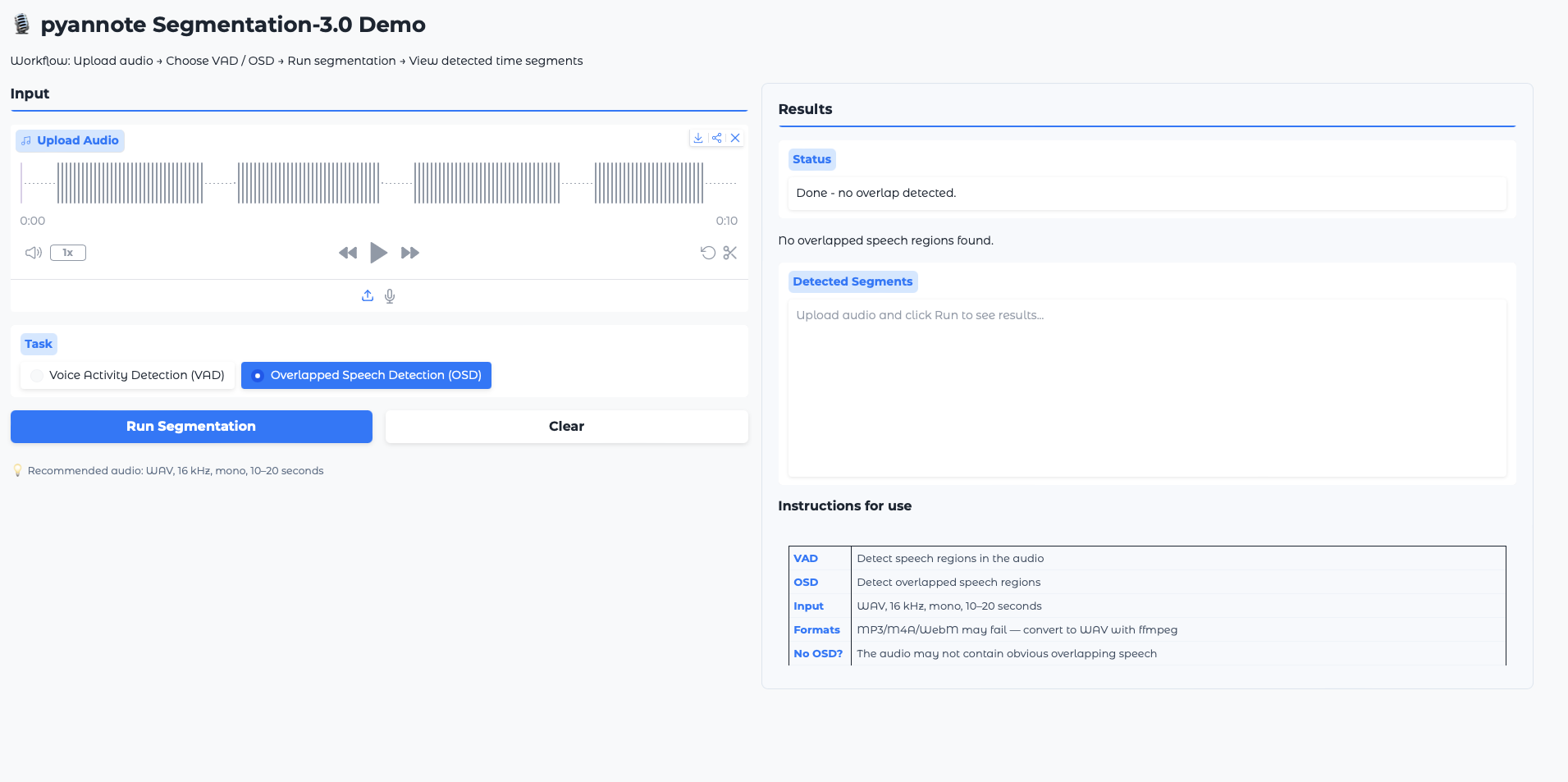

学习扩散语言模型的解码策略
Apple Machine Learning Research
·

何恺明首个语言模型:不走GPT老路,105M参数干翻主流
dotNET跨平台
·

使用扩散生成文本(以及使用LLMs的投资回报)
Stack Overflow Blog
·

通过自回归模型的适应扩展扩散语言模型
Apple Machine Learning Research
·
