本文介绍了多种基于深度学习的抽取式文本摘要模型,强调层级结构和潜变量对摘要质量的重要性。研究表明,数据集的层级结构显著影响模型性能,新模型在多个数据集上取得了优异的ROUGE分数,展示了其在自动摘要领域的潜力。
本文介绍了多个新型摘要数据集及其在学术领域的应用,包括ACLSum、WikiAsp和MS^2,探讨了抽取式与生成式摘要的有效性。研究表明,基于方面的摘要在学术文献中表现优越。此外,SciAssess基准专注于评估大型语言模型在科学文献分析中的能力,确保评估的可靠性和准确性。
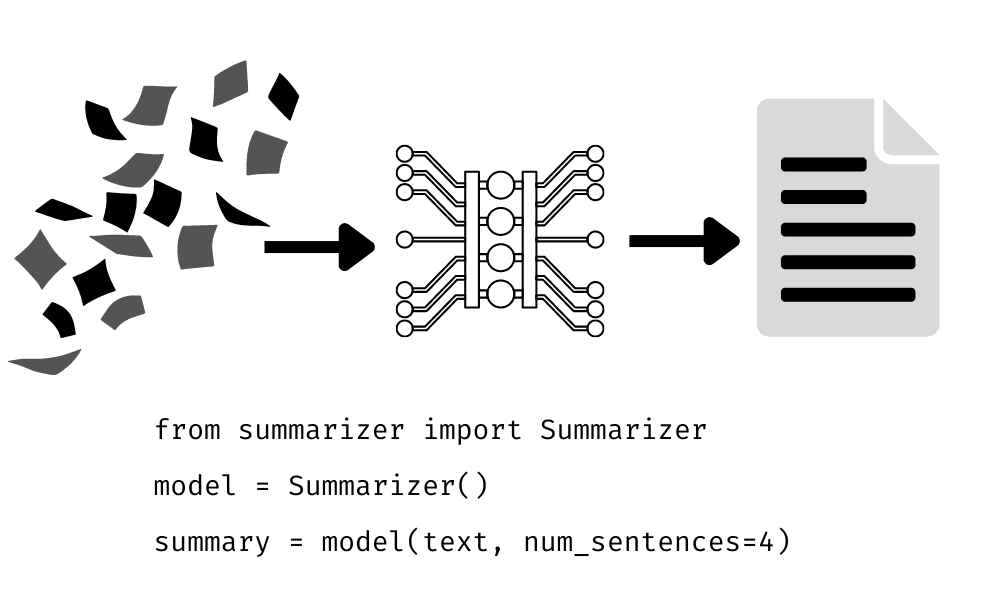
本文介绍了抽取式文本摘要的概念和利用BERT等NLP模型增强它的方法。抽取式摘要通过提取关键句子来快速理解大量文档,具有广泛应用。使用LLMs进行抽取式摘要的过程包括文本解析、特征提取、句子评分和选择汇总。文章还讨论了使用BERT模型进行抽取式摘要的挑战。抽取式摘要是信息泛滥时代的实用工具,随着自然语言处理的发展,它将变得更加重要。
完成下面两步后,将自动完成登录并继续当前操作。