DeepSeek V4 Pro在精度和指令遵循方面优于GPT-5.5 Pro,尤其在复杂任务处理上表现更佳。测试显示,DeepSeek在日志处理和邮件生成等任务中更能准确执行要求,而GPT常常添加多余信息。尽管DeepSeek成本低廉,但推理深度仍不及GPT。社区对评估方法提出质疑,认为样本量小且缺乏科学性。总体来看,DeepSeek提供了“足够好”的性能,但顶尖推理能力仍由GPT和Claude掌握。
腾讯混元推出的新翻译模型Hy-MT2支持33种语言互译,具备强大的指令遵循能力,尤其在金融、政治和教育领域表现优异。该模型提供多种尺寸以适应不同硬件,并支持离线翻译。Hy-MT2已开源,旨在提升机器翻译技术,鼓励社区参与。
本文探讨了AI模型,特别是InstructGPT的意义。作者分析了该模型如何通过人类偏好和指令遵循能力提升性能,强调后训练阶段的重要性。InstructGPT通过模拟人类对话场景,优化了用户与AI的互动,使AI更有效地理解和满足用户需求。最终,作者认为AI的真正能力在于将知识转化为生产力,提升用户体验。
GPT Image 2的底层架构已彻底重构,研究负责人陈博远称其为“通用模型”。团队仅13人,快速取得显著进展,新模型在指令遵循和空间布局方面表现出色,能够精准生成复杂图像。团队成员背景多样,涵盖计算机视觉和机器学习等领域,OpenAI持续吸引跨界人才,推动技术创新。
Anthropic发布了Claude Opus 4.7,提升了指令遵循、视觉、创造力和记忆能力。新模型在复杂任务上表现更佳,但安全性略有下降,用户需调整提示以适应变化。Opus 4.7在金融分析等领域表现出色,并具备自动检测高风险请求的安全措施。
龙虾圈推出的新模型GLM-5-Turbo专为复杂任务优化,解决了通用模型在多步骤执行中的问题。该模型在工具调用、指令遵循和任务持续性方面表现优异,并在ZClawBench评测中获得国产模型第一。GLM-5-Turbo适合个人和企业,支持灵活订阅,提升AI应用效率。
阿里发布了新一代大模型千问Qwen3.5-Plus,具备多模态升级,性能超越GPT-5.2和Claude 4.5,尤其在知识推理和指令遵循方面表现卓越,具备高效推理和自主操作设备的能力。
OpenAI发布了新图像生成模型GPT-Image-1.5,具备更好的指令遵循、精确编辑和细节保留,速度提升4倍。尽管在图像生成和编辑方面表现优异,但在理解世界能力上仍不及Nano Banana,用户反馈存在信息错误。
OpenAI发布了GPT-5.1模型,提升了指令遵循和推理速度,并新增聊天风格选项,允许用户自定义响应。尽管早期移除旧模型引发争议,OpenAI承诺提供过渡期以便用户适应。新Codex-Max模型在编程任务中表现出色,API访问即将推出。
本文提出了一种名为“检查表反馈强化学习”(RLCF)的方法,以提高大型语言模型(LLMs)对用户指令的遵循能力。通过从指令中提取检查表并评估响应的满足程度,RLCF在多个基准测试中表现优异,显著提升了模型的指令遵循性能,表明检查表反馈是改善语言模型支持多样化需求的重要工具。
近期,AI技术迅速发展,但模型在指令遵循方面表现不一。美团M17团队推出Meeseeks评测基准,专注于评估模型的指令遵循能力。评测结果显示,o3-mini系列模型表现优异,Claude系列紧随其后,而DeepSeek和GPT-4o排名较低。Meeseeks通过细化评测框架和多轮纠错模式,揭示了模型的自我纠错潜力,为未来优化提供了方向。
本文介绍了图像生成技术的发展,重点讨论了CLIP和BLIP及其变体的结构与训练方法。CLIP通过对比学习实现图像与文本的匹配,BLIP结合理解与生成能力,提升多模态任务表现。BLIP2引入Q-Former模块,优化视觉与语言对齐,InstructBLIP增强指令遵循能力,适应不同任务需求。
GPT-5是一个统一系统,能够实时选择快速回答模型和深度推理模型。它在减少幻觉、提高指令遵循和安全性方面取得显著进展,尤其在写作、编程和健康领域表现突出。
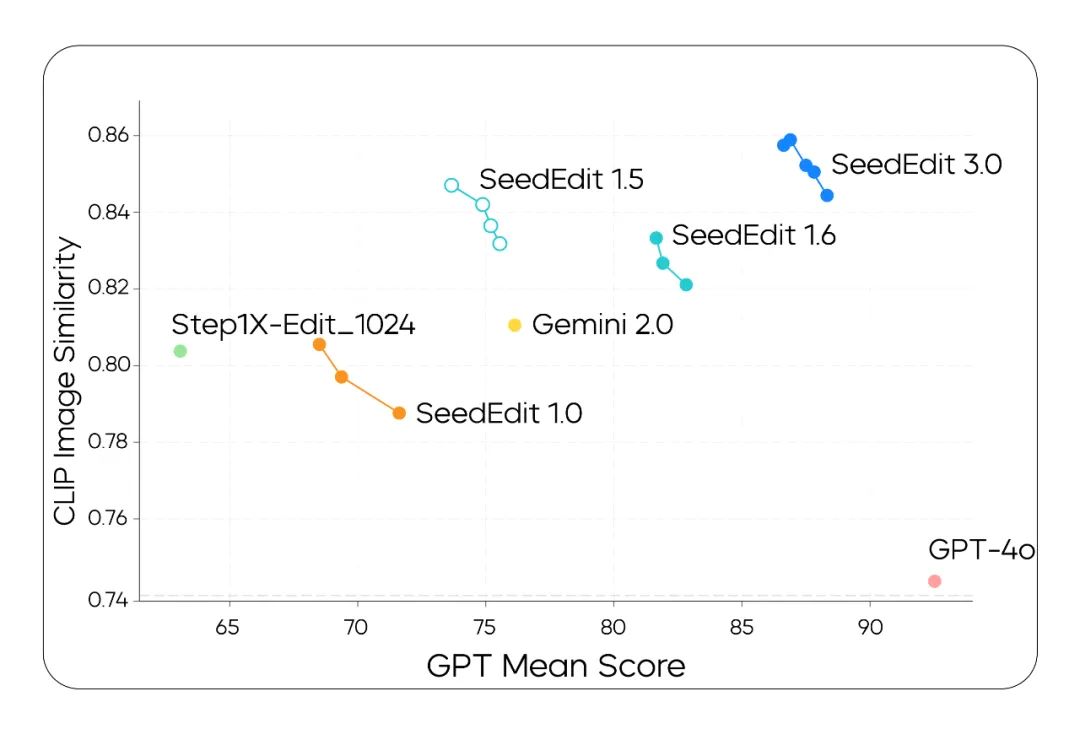
图像编辑模型SeedEdit 3.0基于Seedream 3.0,提升了图像主体、背景和细节的保持能力,尤其在人像编辑和背景更改方面表现突出。该模型支持生成4K图像,指令遵循和可用性显著提高,用户满意度高。团队采用增强型数据策略和多阶段训练,提升了模型的理解能力。尽管表现优秀,指令遵循仍需进一步优化。
研究表明,复杂推理能力强的AI模型在遵循用户指令方面表现较差。上海人工智能实验室与香港中文大学的研究发现,推理能力与指令遵循之间存在权衡关系,模型越智能,越容易忽视具体指令。新基准MathIF用于评估模型的指令遵循程度,结果显示最佳模型仅能遵循50%的指令。
本研究探讨了大型语言模型(LLMs)在遵循自然语言指令方面的不足,提出了MathIF基准以评估数学推理任务中的指令遵循能力。研究表明,提升推理能力与保持模型可控性之间存在矛盾,强调了对更具指令意识的推理模型的需求。
本研究提出WebApp1K基准,评估大规模语言模型在测试驱动开发中的表现,强调模型理解功能、指令遵循和上下文学习的重要性。
本研究提出了一种多维约束框架,用于评估和提升大语言模型的指令遵循能力。该框架包括三种约束模式、四类约束和四个难度等级,生成了1,200个可验证的测试样本,结果显示模型在不同约束下的表现存在显著差异。使用该方法生成的数据显著提高了模型的指令遵循能力。
OpenAI推出了GPT-4.1系列模型,包括常规版、mini版和nano版,专为API调用设计,价格更低。新模型在编程和指令遵循方面有显著改进,支持处理更长内容,性能优于前代。
GPT-4.1系列模型发布,显著提升了编码、指令遵循和长文本理解能力,支持高达100万标记的上下文,性能更优,成本更低。该模型在多个基准测试中表现出色,特别是在编码任务和多轮对话中,提升了指令遵循的可靠性,适用于智能系统和复杂任务的开发。
完成下面两步后,将自动完成登录并继续当前操作。