Grafana 13发布,强调可观察性在优化复杂系统中的重要性。设计仪表板时,应明确目标用户和需求,利用视觉层次引导信息展示,并选择合适的指标(如RED和USE方法)以满足用户需求,持续迭代改进设计。
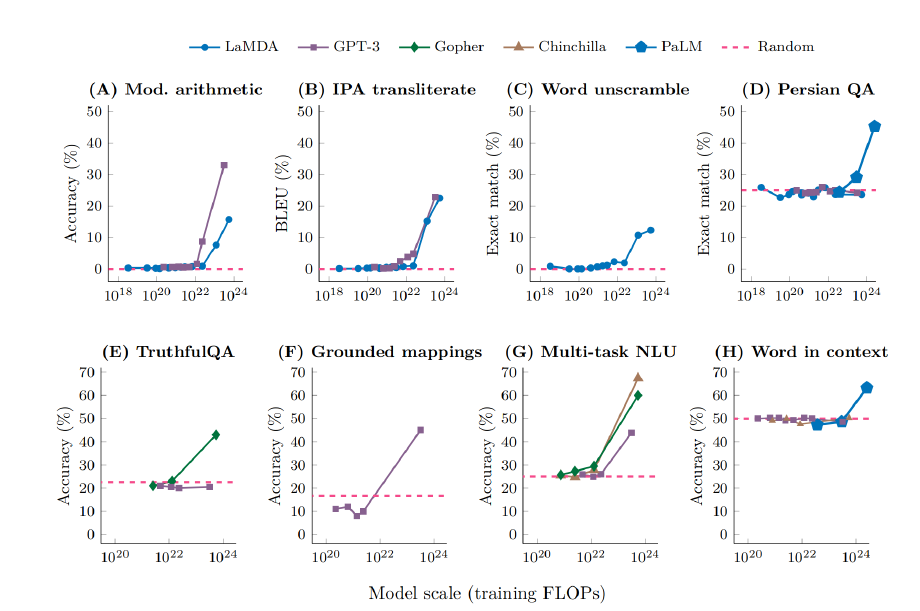
研究人员发现,大规模语言模型的涌现能力是由于衡量指标的选择,而非模型行为的根本性变化。非线性或不连续的衡量标准会导致明显的涌现能力,而线性或连续的度量标准会导致模型性能的平滑、连续、可预测的变化。涌现能力的消失与指标选择相关,不是大规模模型的基本属性。该论文于去年4月底发布,并获得最佳论文奖。
该论文介绍了评估手写文本识别模型的问题,并提出了使用不依赖于真实数据的指标来选择最佳模型的方法。该方法包括使用标准语言模型和遮盖语言模型的复杂方法,并表明遮盖语言模型评估可以与基于词典的方法相竞争。该方法的优点是可以随时使用大型和多语言的Transformer模型。
数据驱动已成为企业的优点,但选择正确的指标和充分理解背景是至关重要的。在健康圈中的例子表明,视角过于狭窄的数据可能会导致错误的决策。销售速度是一个细致的指标,可以帮助你了解实际情况。在商业组织中考虑指标将增加你的知识深度,并帮助你预测下一个季度可能发生的事情以及你可以拉动的杠杆。
完成下面两步后,将自动完成登录并继续当前操作。