
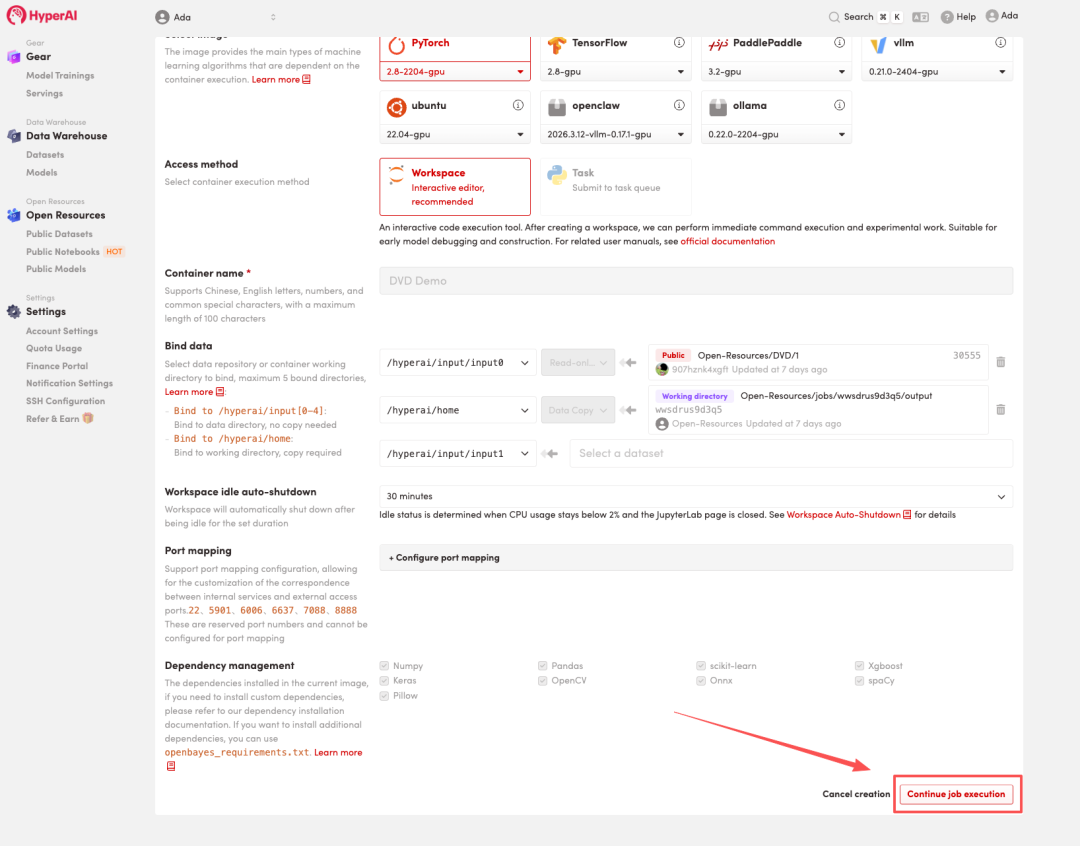
在线教程丨香港科技大学团队开源首个确定性视频深度框架DVD,零样本刷新 SOTA
HyperAI超神经
·

一键调用!京东云率先上线MiniMax M3
京东科技开发者
·

一分钟读论文:《通过自我调节模拟规划实现高效智能体推理》
Micropaper
·

同时服务多个用户:连续批处理如何提高大语言模型推理效率
MachineLearningMastery.com
·
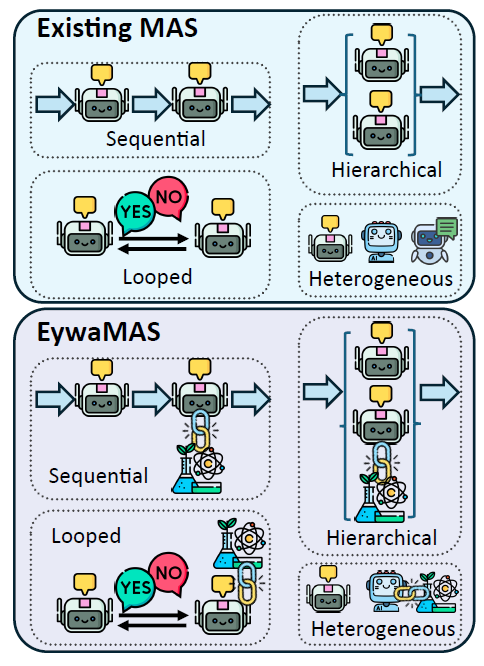

自适应并行推理:高效推理扩展的新范式
The Berkeley Artificial Intelligence Research Blog
·

KernelEvolve:Meta的排名工程师代理如何优化AI基础设施
Engineering at Meta
·
优化吞吐量的Redis用于L2 KV缓存重用
Redis Blog
·

阶跃星辰冲击百亿美金俱乐部,揭开下半场竞争核心逻辑
全球TMT-美通国际
·
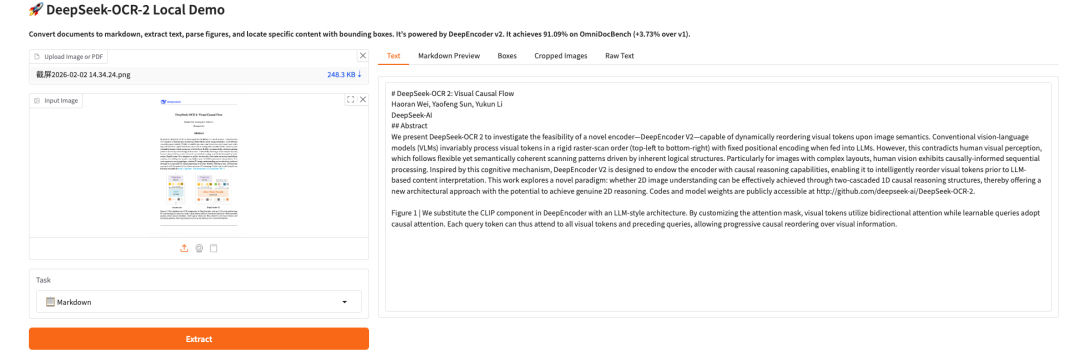

分层大语言模型架构的异步验证语义缓存
Apple Machine Learning Research
·


