Meta的LLaMA-3报告显示,405B模型在54天内发生466次中断,主要由于GPU故障。关键在于高效的checkpoint机制,包括异步写入和分布式存储。有效的故障容忍策略如热备节点、健康检查和自动识别慢节点,可以优化恢复时间,提高有效训练时间,从而降低成本,确保训练按期完成。
Postgres和Kafka是为不同目的设计的工具,不能简单替代。虽然Postgres在某些情况下有效,但Kafka在事件流处理、可扩展性和故障容忍方面具有独特优势。选择合适的工具至关重要,通常同时使用两者更为合理。
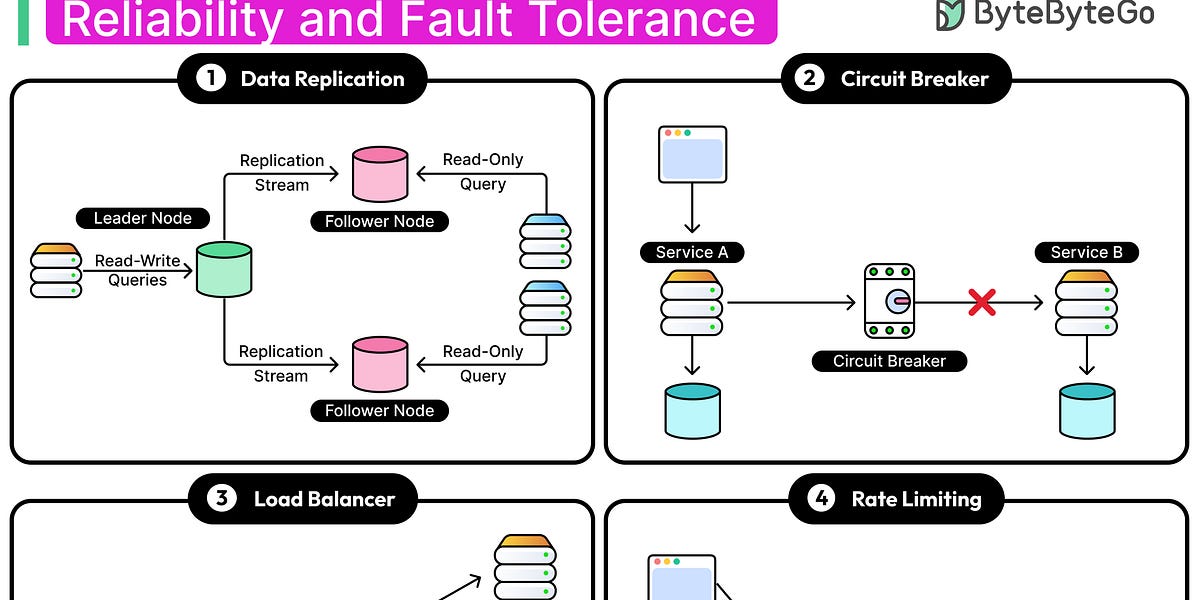
分布式系统常面临节点崩溃和网络中断等故障,设计目标在于构建能够吸收和恢复的系统,而非消除故障。系统的可靠性依赖于组件间的互动,通过故障容忍、负载均衡、速率限制和服务发现等策略,可以提升系统的可靠性,形成弹性架构。
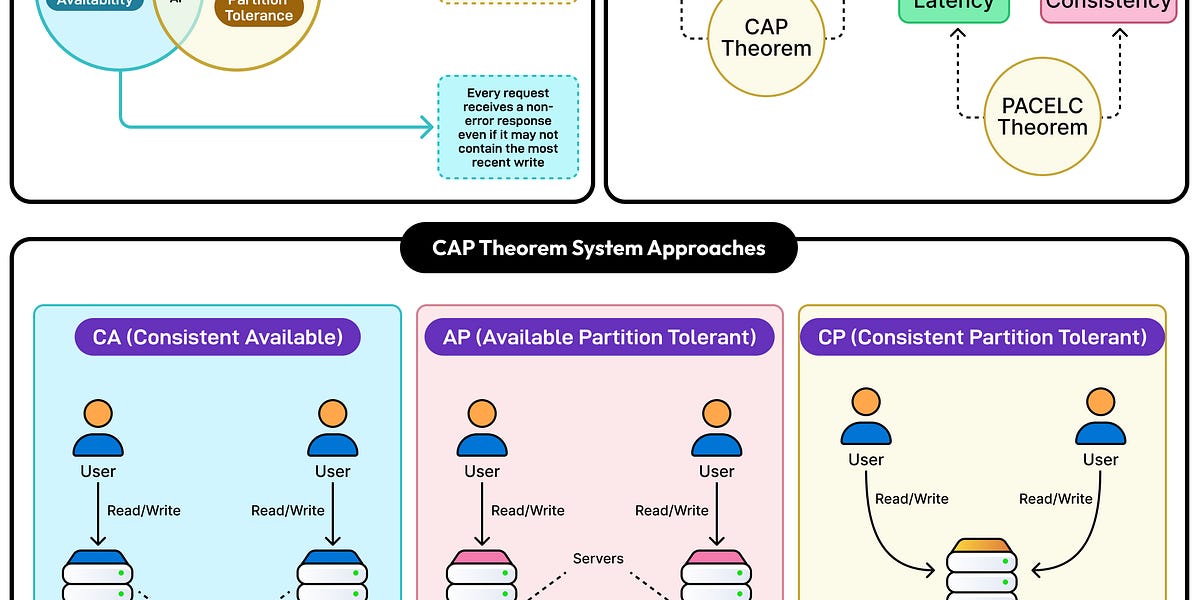
现代数据库已实现跨区域和节点的数据复制与并行查询处理。随着系统扩展,故障容忍与正确性之间的矛盾逐渐显现,数据库需在可用性与一致性之间权衡,CAP定理和PACELC定理有助于理解这些权衡。
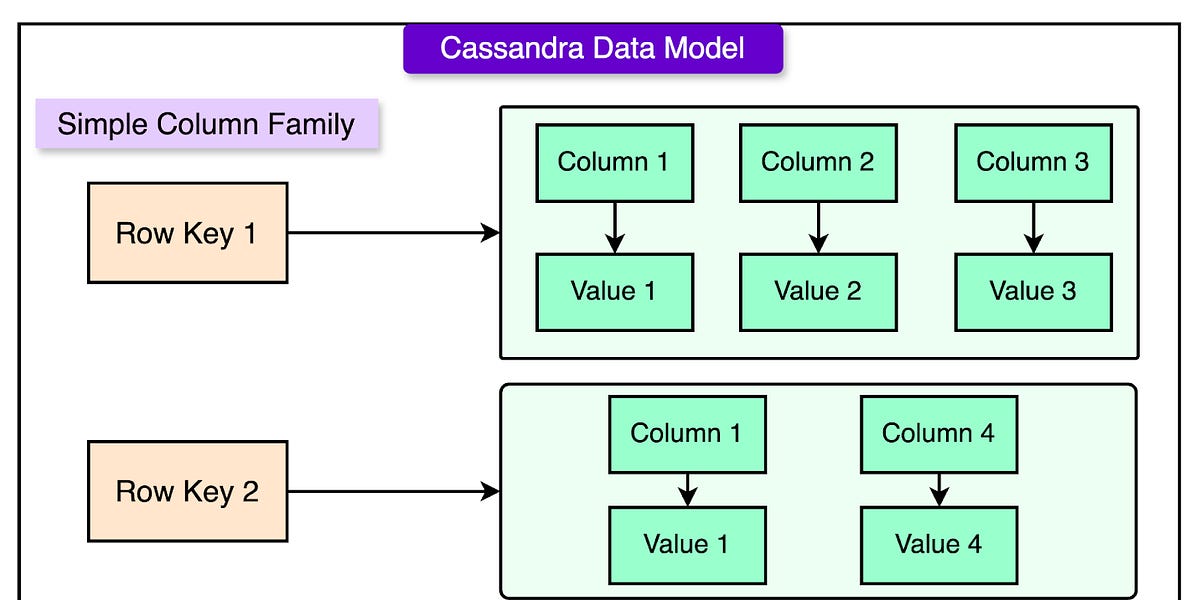
Cassandra是一个高可扩展的分布式数据库,专为处理大量数据而设计,具备故障容忍和高可用性。其对等架构和环形设计使其适合需要持续运行和无缝扩展的应用,如消息平台和物联网数据存储。
完成下面两步后,将自动完成登录并继续当前操作。