
Facebook的数据库处理数十亿条消息(Cassandra深度解析)
内容提要
Cassandra是一个高可扩展的分布式数据库,专为处理大量数据而设计,具备故障容忍和高可用性。其对等架构和环形设计使其适合需要持续运行和无缝扩展的应用,如消息平台和物联网数据存储。
关键要点
-
Cassandra是一个高可扩展的分布式数据库,专为处理大量数据而设计。
-
Cassandra具备故障容忍和高可用性,适合需要持续运行和无缝扩展的应用。
-
Cassandra的对等架构和环形设计使其能够高效存储和搜索海量数据。
-
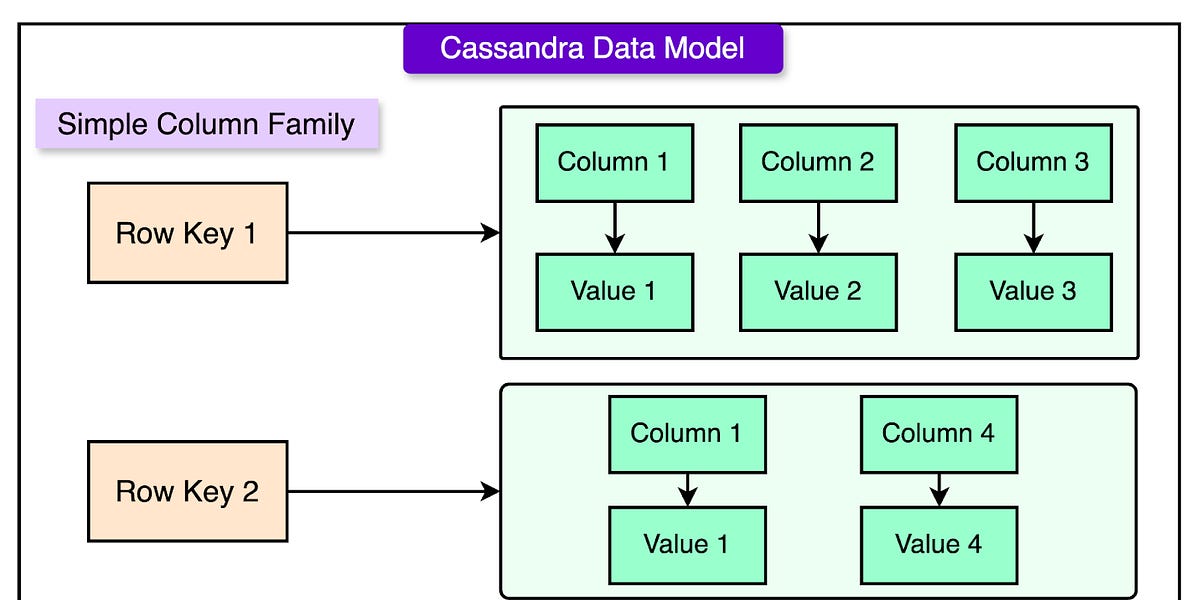
Cassandra的数据模型与传统关系数据库不同,采用多维映射的方式存储数据。
-
Cassandra的API结构简单,主要包括插入、检索和删除数据的操作。
-
Cassandra采用无中心的对等模型,确保没有单点故障,所有节点平等。
-
Cassandra使用复制机制确保数据安全,支持多种复制策略以提高可用性。
-
Cassandra通过Gossip协议实现节点间的高效通信,确保系统状态的实时更新。
-
Cassandra的写入和读取过程优化了速度和可靠性,采用日志结构存储模型。
-
Cassandra最初为Facebook的Inbox Search开发,能够高效处理海量消息的存储和搜索。
-
Cassandra适合实时应用,如消息平台和物联网数据存储,但不适合复杂查询和事务一致性要求的应用。
延伸解读
Cassandra的优势与应用场景
Cassandra的分布式架构和高可用性使其非常适合处理实时应用,如消息平台和物联网数据存储。其无中心的对等模型确保了系统的稳定性,避免了单点故障的风险。对于需要快速写入和读取的场景,Cassandra表现出色,能够支持大规模用户的需求。
与传统数据库的对比
与传统关系数据库(如MySQL)相比,Cassandra在处理海量数据时更具优势。传统数据库在扩展性和高并发写入方面存在瓶颈,而Cassandra通过其环形设计和多维数据模型,能够轻松应对不断增长的数据量和复杂查询的挑战。
使用Cassandra的注意事项
尽管Cassandra在高可用性和扩展性方面表现优异,但它并不适合所有应用。对于需要复杂查询和事务一致性的场景,Cassandra可能无法满足需求。因此,在选择数据库时,开发者应根据具体应用场景评估其适用性。
延伸问答
Cassandra是什么类型的数据库?
Cassandra是一个高可扩展的分布式数据库,专为处理大量数据而设计。
Cassandra的主要特点有哪些?
Cassandra具备分布式存储、高可用性、无单点故障和可扩展性等特点。
Cassandra是如何处理数据写入的?
Cassandra通过先记录在Commit Log中,然后存储在Memtable中,最后将数据写入SSTables来处理数据写入。
Cassandra的API结构是怎样的?
Cassandra的API结构简单,主要包括插入、检索和删除数据的操作。
Cassandra如何确保数据的高可用性?
Cassandra通过复制机制将数据复制到多个节点,确保即使部分节点故障也能继续工作。
Cassandra最初是为哪个应用开发的?
Cassandra最初是为Facebook的Inbox Search开发的,旨在高效处理海量消息的存储和搜索。
