

如何使用ggplot2在R中创建散点图和建模数据
freeCodeCamp.org
·

如何使用Python和Textualize在终端中绘图
Mouse Vs Python
·

解决 Matplotlib Scatter 不支持 Marker 列表的问题:mscatter 实现
plus studio
·
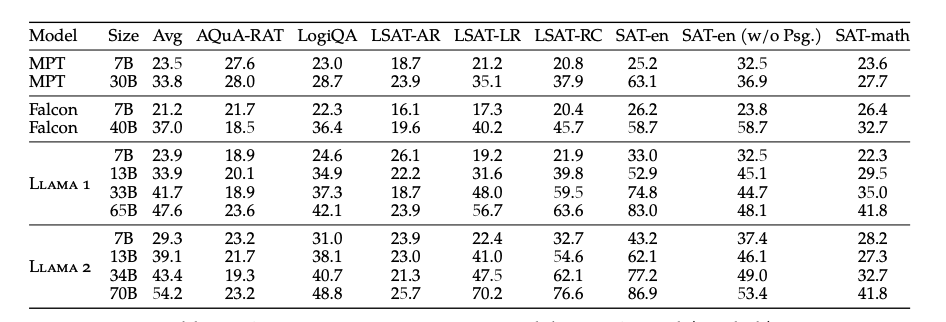
GPT-4V在一般问题、具体问题及链式思维提示(COT)技术上的实验
Blog on LlamaIndex
·
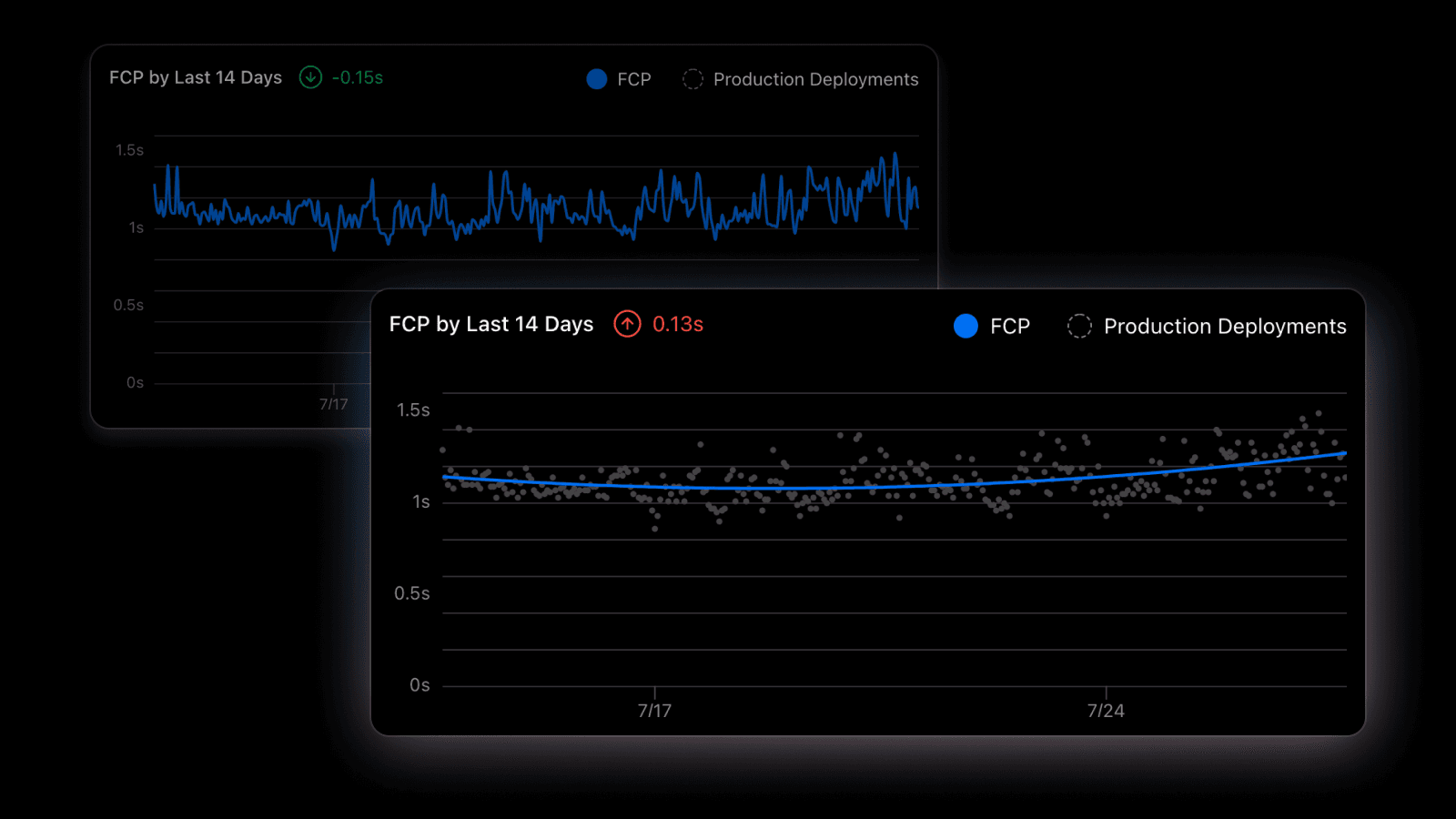
Vercel Analytics 图表的准确性提升
Vercel News
·

第475期
蠎周刊
·
