
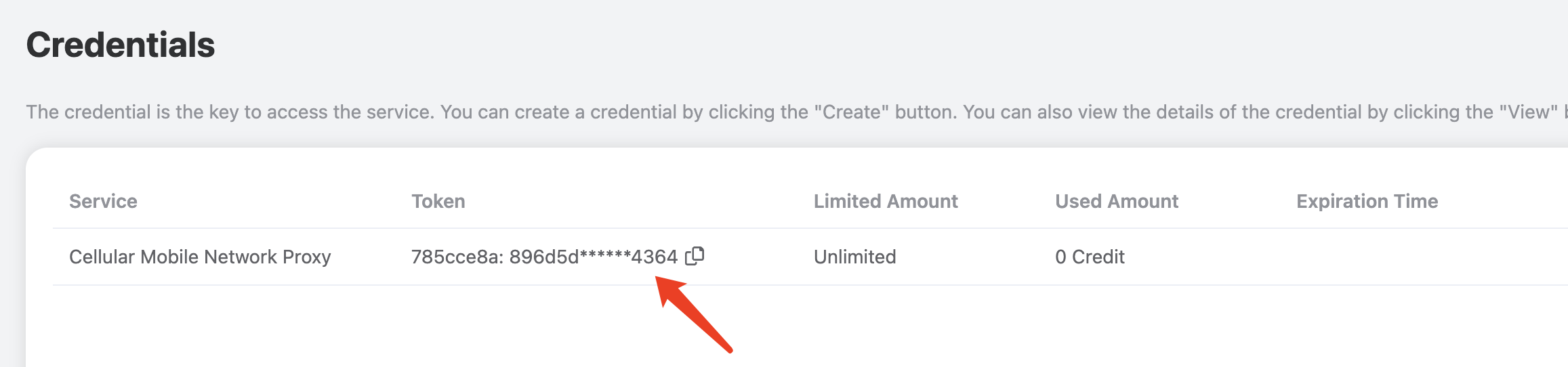
移动蜂窝代理对接说明
静觅
·

基于 Cloudflare Workers 实现的在线服务状态检测告警系统
竹林里有冰的博客
·

代理IP高效助力数据爬取百万级数据
DEV Community
·

如何应对数据爬取中频繁IP访问导致的问题?
DEV Community
·

AI通过大规模抓取网络数据正在自我毒害
Jina AI
·

某微信爬虫工具多开方案
崎径 其镜赵安琪的博客
·
