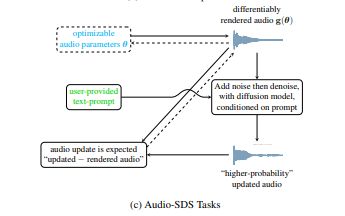
音频扩散模型已实现高质量音频合成,但参数优化不足。研究者提出Audio-SDS方法,结合预训练模型,优化音频表示,支持FM合成和源分离等任务,提升合成效果与文本提示的一致性,展示了数据蒸馏在音频领域的潜力。
深度求索于1月开源了DeepSeek-R1模型,提出数据蒸馏方案,通过小模型精调训练,效果与OpenAI o1-mini相当。飞桨框架3.0优化推理能力,支持高效部署,显著提升模型性能并降低成本。
上交大EPIC实验室提出的新数据蒸馏方法NFCM,使用2080Ti显卡仅需2GB内存,显著提升性能和速度。该方法将数据蒸馏转化为minmax优化问题,优化合成数据质量,适用于多个基准数据集,表现优异。
大型语言模型(LLMs)改变了与人工智能的互动方式,但API使用成本高。为降低令牌使用而不影响输出质量,提示压缩至关重要。本文介绍了微软研究人员的LLMLingua-2方法,通过数据蒸馏实现高效的任务无关提示压缩,降低成本同时保持性能。
本文介绍了一种新的基于核的元学习框架,利用无限宽卷积神经网络在数据集压缩中取得了优异成果。研究分析了多个数据集的压缩效果,并提出了改进合成训练数据泛化性能的方法,通过课程数据增强和新评估方法ELF,显著提升了在大规模数据集上的准确性,推动了数据集蒸馏技术的发展。
完成下面两步后,将自动完成登录并继续当前操作。