
NVIDIA AI 推出 Audio-SDS:基于扩散的统一框架,无需专门数据集即可实现提示引导音频合成和源分离
内容提要
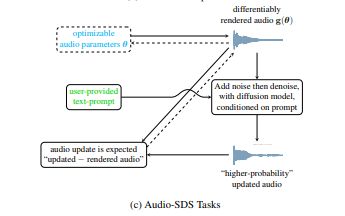
音频扩散模型已实现高质量音频合成,但参数优化不足。研究者提出Audio-SDS方法,结合预训练模型,优化音频表示,支持FM合成和源分离等任务,提升合成效果与文本提示的一致性,展示了数据蒸馏在音频领域的潜力。
关键要点
-
音频扩散模型已实现高质量音频合成,但参数优化不足。
-
研究者提出Audio-SDS方法,结合预训练模型,优化音频表示。
-
Audio-SDS支持FM合成和源分离等任务,提升合成效果与文本提示的一致性。
-
SDS通过预训练扩散先验进行反向传播,优化参数化音频表示。
-
Audio-SDS框架结合数据驱动的先验与明确的参数控制,产生高质量音频。
-
关键改进包括基于稳定解码器的SDS、多步去噪和多尺度频谱图方法。
-
Audio-SDS在FM合成、冲击声合成和源分离任务中表现出色。
-
实验使用主观和客观指标测试框架有效性,结果显示合成效果显著提升。
-
Audio-SDS展示了基于数据蒸馏的方法在音频相关任务中的潜力。
延伸解读
Audio-SDS的创新意义
Audio-SDS方法通过结合预训练模型和数据蒸馏技术,显著提升了音频合成的质量和一致性。这一创新不仅减少了对特定数据集的依赖,还为音频生成领域提供了新的思路,尤其是在处理复杂音频任务时,展现出更高的灵活性和可解释性。
应用场景与潜在挑战
Audio-SDS在FM合成、冲击声合成和源分离等任务中表现出色,适用于多种音频生成需求。然而,模型在覆盖率和优化灵敏度方面仍面临挑战,用户在实际应用时需关注这些潜在问题,以确保生成音频的质量和稳定性。
数据蒸馏的前景
Audio-SDS展示了数据蒸馏在音频领域的应用潜力,尤其是在无需大量特定数据集的情况下,仍能实现高质量的音频合成。这为未来的音频技术发展提供了新的方向,可能推动更多基于数据驱动的方法在音频生成中的应用。
延伸问答
Audio-SDS方法的主要创新点是什么?
Audio-SDS结合了预训练模型和数据驱动的先验,优化音频表示,支持多种音频任务。
Audio-SDS如何提升音频合成的效果?
通过多步去噪和多尺度频谱图方法,Audio-SDS提高了高频细节和真实感。
Audio-SDS支持哪些音频任务?
Audio-SDS支持FM合成、冲击声合成和源分离等任务。
Audio-SDS的实验验证了什么?
实验显示Audio-SDS在音频合成和分离方面的效果显著提升,并与文本提示一致。
Audio-SDS如何处理参数优化问题?
Audio-SDS通过反向传播优化参数化音频表示,避免了构建大型特定任务数据集的需求。
Audio-SDS在音频领域的潜力是什么?
Audio-SDS展示了基于数据蒸馏的方法在音频合成和源分离等任务中的潜力。
