


服务地理空间、视觉及更多:在vLLM中实现多模态输出处理
vLLM Blog
·
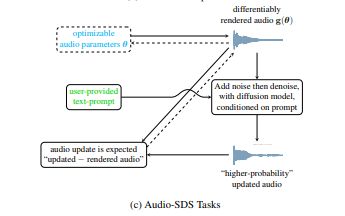

构建一个开源AI的PDF转播客管道:从文本提取到语音合成
DEV Community
·
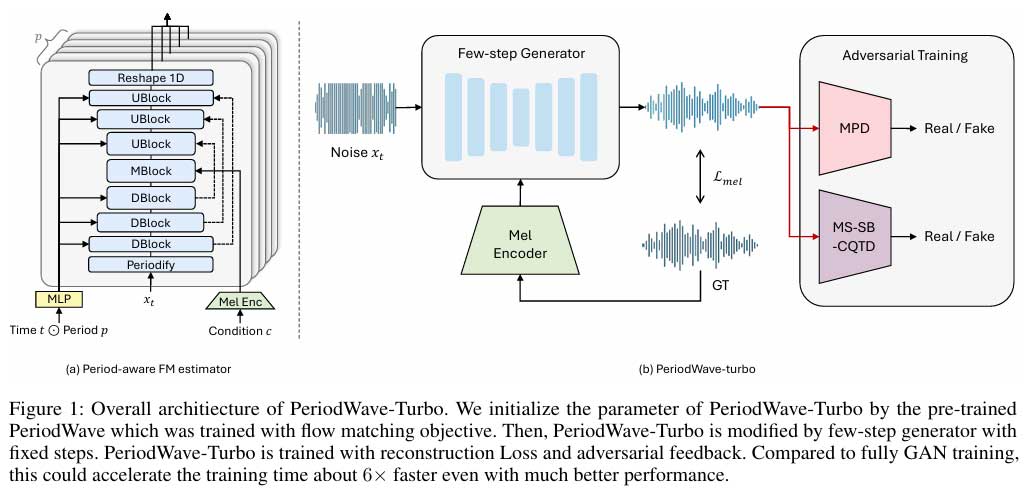
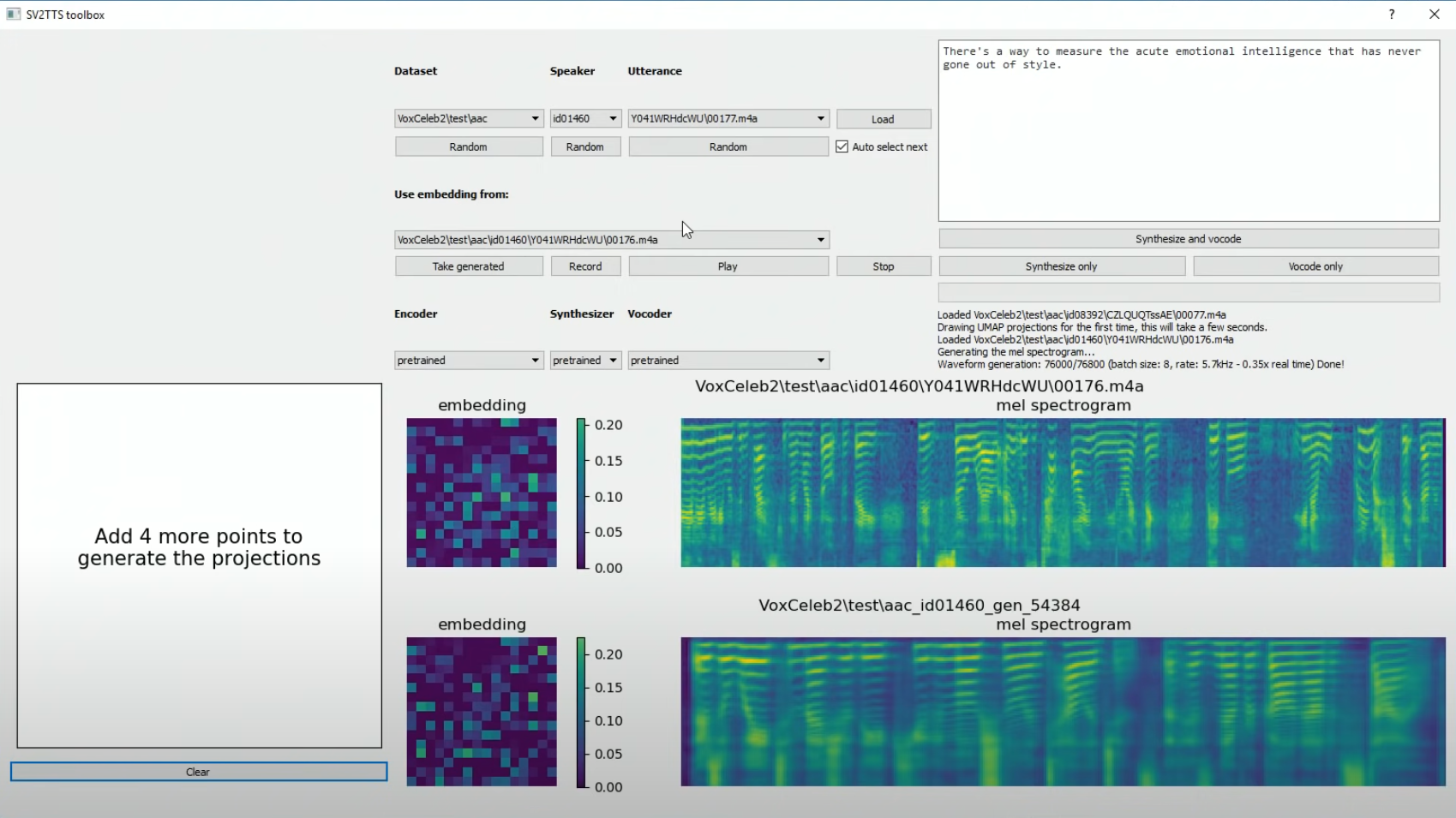
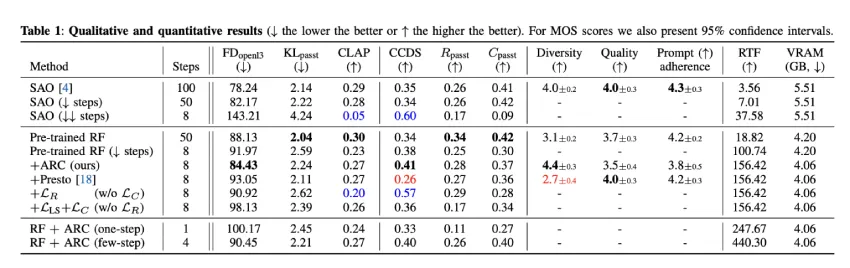
从声纹模型到语音合成:音频处理 AI 技术前沿 | 开源专题 No.45
开源服务指南
·
