本研究提出了一种超轻量级预测模型Alinear,质疑了时间序列预测中的缩放法则。Alinear通过动态调整成分权重和频率衰减策略,在使用不足1%参数的情况下,依然保持了强大的准确性,挑战了“大模型更好”的传统观念。
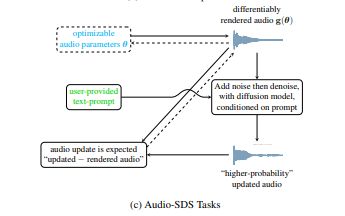
音频扩散模型已实现高质量音频合成,但参数优化不足。研究者提出Audio-SDS方法,结合预训练模型,优化音频表示,支持FM合成和源分离等任务,提升合成效果与文本提示的一致性,展示了数据蒸馏在音频领域的潜力。
本研究利用机器学习自动化模拟和射频电路设计,显著缩短参数优化时间。通过监督学习评估多种模型,发现其在异构电路中的准确性提高了88%,展示了方法的可扩展性和准确性。
本文提出三种可插拔的解码器,采用神经记忆常微分方程的不同离散化方法,解决U形网络在医疗图像分割中的参数过多和计算复杂度高的问题。实验结果表明,这些解码器有效减少了20%至50%的参数和最高74%的FLOPs,同时保持了性能。
本研究提出了一种阿拉伯稳定语言模型1.6B,旨在解决阿拉伯语言处理中的参数过多和硬件要求高的问题。该模型在多个基准测试中表现优越,为低资源语言研究提供了更轻量级的选择。
本研究提出了一种通过预训练神经网络增强变分量子电路(VQC)的方法,旨在解决量子比特数量限制带来的潜力不足问题,提高参数优化效率,并在量子点分类任务中取得显著成果,展现出广泛的应用潜力。
该研究改进了点线SLAM系统,通过将方向相似的线锚定到主轴上,并用$n+2$个参数优化,解决了线结构信息利用不足的问题。此方法不仅考虑了场景结构信息,还减少了需优化的线参数,提高了映射和跟踪的速度和准确性。实验验证了其在多种数据集上的有效性。
作者提出了一个提升效率的想法:每个常规动作提高1%。他在项目中实现了打开文章、评论和个人资料的功能,并计划优化参数传递。他正在研究如何在应用中显示网页格式的文本。接下来,他将添加静态代码分析工具Detekt,更新项目说明,并创建GitHub项目以便协作。他寻求设计师和开发者的帮助,并列出了详细的时间计划。
本文介绍了一种新颖的非远见自适应高斯过程规划框架,旨在优化机器人算法参数并确保安全性。研究提出了多种安全贝叶斯优化算法,结合动态环境和高维问题,提升了优化效率和安全性,适用于复杂控制系统的参数优化。
Rclone + Onedrive参数优化:启用fast_list、onedrive_av_override、onedrive_no_versions、onedrive_server_side_across_configs;禁用Onedrive的版本控制;使用PowerShell全局禁用版本控制;使用特定账户设置禁用版本控制。
本文提出了实现高质量实时1080p新视图合成的关键要素,包括3D高斯函数表示、参数优化和可见性感知渲染算法。研究中介绍的RadSplat方法通过优化点表示,提高了渲染质量和速度,达到了900帧每秒的性能。此外,文中还综述了3D高斯喷涂方法的进展及其在形状重建和渲染中的应用潜力。
近年来,大型语言模型(LLM)在自然语言处理领域取得了显著进展,但也面临保留错误知识的风险。为了解决这一问题,研究者提出了知识遗忘的概念,主要包括参数优化、参数合并和上下文学习三种方法。研究强调了有效评估遗忘的重要性,并探讨了其在隐私保护和减少社会技术危害方面的应用。实验结果显示,现有方法在实践中仍需改进,以实现更高效的知识遗忘。
本文介绍了优化Stable Diffusion XL模型的方法,包括基本优化、Pipeline优化和组件优化。作者推荐了使用OneDiff引擎进行图片/视频推理加速。还介绍了调整步数和使用Tiny VAE模型等参数优化方法。这些优化方法可以提高生成速度和减少内存使用,但可能会牺牲图像质量。
本文介绍了概率模型优化中的潜变量问题和期望最大化(EM)算法。EM算法通过交替的期望(E)步骤和最大化(M)步骤来优化概率模型参数。
该研究提出了一种用于顺序推荐的多任务模型CL4SRec,通过提取用户行为序列中的有意义模式和编码用户表示,解决了数据稀疏性和参数优化问题,在四个公共数据集上取得了领先性能。
本研究通过优化电极设计和参数,采用了一种新的基于强化学习的二进制粒子群优化方法(RLBPSO),在不同频率范围内显示出最佳的优化设计。
完成下面两步后,将自动完成登录并继续当前操作。