世界充满疑问,软件开发如梦。慢思考与死亡学习至关重要,记录日常是个人历史。多说“我不知道”,观察世界变化。文化理解与再设计稀缺,处理事务方式多样,需不断练习。
我们致力于让AGI惠及全人类,特别是非英语国家。为此,我们创建了IndQA,这是一个评估印度语言和文化理解的新基准,涵盖2278个问题,涉及12种语言和10个文化领域,旨在评估AI的理解和推理能力,促进技术在印度的可及性和应用。
作者分享了学习多种语言的经历,指出西班牙语对他来说比母语和英语更具挑战性,因未能深入理解西班牙文化。尽管在表达上遇到困难,他认为这种挑战有助于大脑锻炼。他强调,流利程度影响表达能力,掌握语言不仅是词汇的积累,更是文化理解的体现。
视频会议中的实时翻译技术正在迅速进步,虽然支持多种语言,但仍面临准确性不足和文化细节缺失的问题。Zoom、Teams和Google Meet等平台正在整合AI翻译功能,未来的翻译工具将更加关注情感和文化理解。然而,在关键对话中,人工翻译仍然不可或缺。
本研究提出LLM-C3MOD系统,旨在改善低资源语言中仇恨言论管理的文化理解不足问题。通过增强文化背景注释和人工管理,该系统提高了分析准确性,减轻了人类调节者的工作量。研究表明,适当支持的非母语调节者能够有效参与跨文化仇恨言论管理。
大型语言模型(LLMs)为印度语言的理解和交流带来了新机遇。尽管面临数据稀缺等挑战,LLMs在提升语言能力和文化理解方面展现出巨大潜力。通过透明的数据共享和多样化的数据集,未来有望实现更好的语言处理效果。
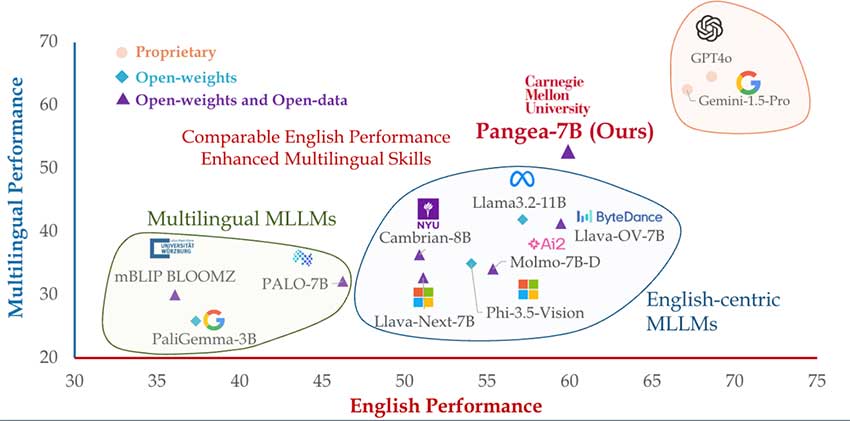
尽管多模态大型语言模型(MLLM)在英语上取得进展,但全球语言和文化的代表性仍不足。卡内基梅隆大学推出的PANGEA模型,使用包含39种语言的600万个样本的数据集PANGEAINS进行训练。评估结果显示,PANGEA在多语言任务上优于现有模型,并在多元文化理解方面表现突出。该模型的开源有望提升跨语言和文化的公平性与可访问性。
本文评估了多模态大型语言模型(MLLMs)在低层视觉感知和理解方面的能力,发现其基本技能不稳定且不精确。通过多个基准测试,尤其是针对中国高考的GAOKAO-MM,模型的准确率普遍低于50%。研究还揭示了视觉-语言模型(VLMs)在文化理解方面的西方偏见,并提出了改进建议。
本文介绍了多语言视觉问答基准的构建与评估,包括xGQA、MaRVL、MTVQA和CVQA,探讨了跨语言视觉问答的挑战及改进策略。研究表明,现有模型在多语言环境中的表现不佳,尤其在文化理解和低资源语言方面存在显著差距,强调了进一步研究的必要性。
该研究构建了适应韩国文化的视觉-语言模型(VLM)数据集,评估了模型在文化理解上的表现,发现开源模型落后于专有模型。通过问卷调查和基准测试,揭示了模型在文化多样性和低资源语言上的挑战,并提出了改进建议,强调增强文化意识和语言多样性的必要性。此外,研究引入了文化意识分数(CAS)作为新评估指标,以推动文化敏感性AI系统的发展。
完成下面两步后,将自动完成登录并继续当前操作。