
CMU 研究人员发布 Pangea-7B:适用于 39 种语言的完全开放多模态大型语言模型 MLLM
内容提要
尽管多模态大型语言模型(MLLM)在英语上取得进展,但全球语言和文化的代表性仍不足。卡内基梅隆大学推出的PANGEA模型,使用包含39种语言的600万个样本的数据集PANGEAINS进行训练。评估结果显示,PANGEA在多语言任务上优于现有模型,并在多元文化理解方面表现突出。该模型的开源有望提升跨语言和文化的公平性与可访问性。
关键要点
-
多模态大型语言模型(MLLM)在英语上取得进展,但全球语言和文化代表性不足。
-
卡内基梅隆大学推出的PANGEA模型,使用包含39种语言的600万个样本的数据集PANGEAINS进行训练。
-
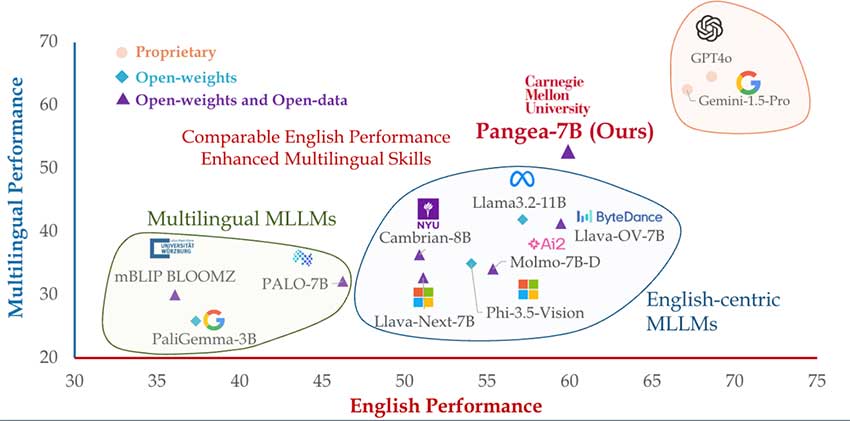
PANGEA在多语言任务上优于现有模型,并在多元文化理解方面表现突出。
-
PANGEAINS数据集结合高质量的英语教学、机器翻译教学和文化相关的多模态任务。
-
PANGEABENCH评估套件涵盖14个数据集和47种语言,深入评估PANGEA的能力。
-
PANGEA-7B模型在英语任务上平均提升7.3分,在多语言任务上平均提升10.8分。
-
PANGEA在多元文化理解方面表现出色,跨语言能力均衡。
-
PANGEA在多个领域的表现与Gemini-1.5-Pro和GPT4o等专有模型相当甚至更好。
-
PANGEA的开源有望促进跨语言和文化的公平性与可访问性。
-
未来需要改进多模式聊天和复杂推理任务的性能。
延伸解读
多语言模型的必要性
随着全球化的加速,语言和文化的多样性愈发重要。PANGEA模型的推出,正是为了填补现有多模态大型语言模型在非英语语言和文化代表性上的空白。这一进展不仅有助于提升模型在多语言环境中的表现,也为不同文化背景的用户提供了更公平的技术支持。
开源的潜在影响
PANGEA及其数据集的开源将为研究人员和开发者提供宝贵的资源,促进多语言和多模态技术的发展。这种开放性有助于推动跨文化交流和理解,降低技术壁垒,使更多非英语用户能够受益于先进的语言模型。
未来的挑战与改进方向
尽管PANGEA在多语言任务上表现优异,但仍需关注其在多模式聊天和复杂推理任务中的性能不足。未来的研究应集中于这些领域的改进,以确保模型在更广泛的应用场景中保持高效和准确。
延伸问答
PANGEA模型的主要特点是什么?
PANGEA模型是一种多语言多模态语言模型,支持39种语言,使用600万个样本的数据集进行训练,旨在提升全球语言和文化的代表性。
PANGEAINS数据集的构建方法是什么?
PANGEAINS数据集通过翻译高质量的英文指令、生成文化意识任务和整合现有的开源多模态数据集来构建,旨在解决数据稀缺和文化差异问题。
PANGEA在多语言任务上的表现如何?
PANGEA在多语言任务上平均提升10.8分,表现优于许多现有模型,显示出其强大的跨语言能力。
PANGEA模型的开源有什么意义?
PANGEA模型的开源有望促进跨语言和文化的公平性与可访问性,推动多语言多模态模型领域的发展。
PANGEA在多元文化理解方面的表现如何?
PANGEA在多元文化理解方面表现出色,尤其在CVQA和xChat基准测试中显示出其优势。
PANGEA与其他模型相比有什么优势?
PANGEA在多个领域的表现与Gemini-1.5-Pro和GPT4o等专有模型相当甚至更好,显示出其作为竞争对手的实力。
