黄仁勋在卡耐基梅隆大学的演讲中鼓励毕业生不要害怕AI,认为他们正处于充满机会的时代。他分享了自己的奋斗经历,强调AI将改变就业市场并创造新机会。尽管有人担心AI可能导致失业,黄仁勋呼吁年轻人积极适应变化,勇敢面对挑战,努力学习。
抱歉,您提供的文本内容过于简短,无法进行有效的总结。请提供更多信息或更长的文章内容。
CMU研究发现,数学能力强的大模型在其他领域的表现有限。只有通过强化学习(RL)训练的模型能够有效迁移数学推理技能,而监督微调(SFT)可能导致负迁移。研究表明,微调方法是影响迁移能力的关键,RL模型在保持原有知识的同时提升了特定领域的表现。
机器之心数据服务现已上线,提供高效稳定的数据获取服务,简化了数据爬取流程。
机器之心数据服务现已上线,提供高效稳定的数据获取,简化数据爬取流程。
本文探讨了内存数据库与传统磁盘数据库的设计差异。内存数据库将数据常驻内存,避免了磁盘访问延迟,从而提升性能。尽管内存数据库在现代应用中日益普及,但在高并发情况下仍需关注锁竞争和时间戳分配等瓶颈问题。
机器之心数据服务现已上线,提供高效稳定的数据获取服务,帮助用户轻松获取所需数据。
本研究针对多模态情感分析中的不足,采用基于变压器的模型通过早期融合整合文本、音频和视觉信息。研究结果显示,该模型在测试集上实现了97.87%的七分类准确率和0.9682的F1分数,展示了早期融合在跨模态交互捕捉方面的有效性。
HPE Insight集群管理工具v8.2存在关键无认证远程代码执行漏洞(CVE-2024-13804),攻击者可绕过认证以root权限执行任意命令。该漏洞源于设计缺陷,影响高性能计算集群管理。HPE已停止发布安全补丁,建议用户实施网络隔离以降低风险。
大语言模型(LLM)通过元强化微调(MRT)优化推理能力,研究表明MRT在多个基准测试中优于传统的结果奖励强化学习(RL),在准确率和token效率上均有显著提升。MRT通过平衡探索与利用,优化LLM输出,推动解决更复杂的问题。
#09 - Search Parallelization: Bottom-up (CMU Optimize!)
清华与CMU团队的研究表明,长思维链(CoT)推理能力可以通过强化学习(RL)实现,监督微调(SFT)并非必需,但能提升效率。研究强调奖励函数对CoT扩展的重要性,并指出模型具备自我纠错能力。未来的研究将集中在模型规模和RL基础设施的改进上。
英伟达与卡内基梅隆大学合作开发ASAP框架,使宇树机器人能够模仿篮球明星科比的复杂投篮动作。该框架通过预训练和真实数据收集,显著提升了机器人的灵活性和协调性。研究团队主要由华人组成,期待2030年“人形”奥运会的到来。
AI 社区讨论 Scaling Law 遇到瓶颈,因高质量数据即将耗尽。CMU 和 DeepMind 提出的 ICAL 方法利用低质量数据和反馈,帮助 LLM 和 VLM 创建有效提示,改善决策。ICAL 强调认知抽象,提升模型在新任务中的表现,实验表明其在多模态任务中优于传统方法,减少对专家示例的依赖。
研究表明,具身智能和大型语言模型(LLM)均易受越狱攻击。卡耐基梅隆大学的研究发现,攻击者可轻易破解LLM控制的机器人,带来安全隐患。越狱攻击不仅影响文本生成,还可能影响机器人在现实中的行为,因此需加强防御措施。
卡内基梅隆大学提出了一种新型黑盒优化策略,利用大语言模型自动调整视觉语言模型的提示词,无需访问模型参数。这种方法提高了优化的灵活性和速度,适用于多种视觉任务,并在多个数据集上超越传统方法。研究表明,该策略能够有效捕捉视觉特性,生成高质量图像,具有广泛的应用潜力。
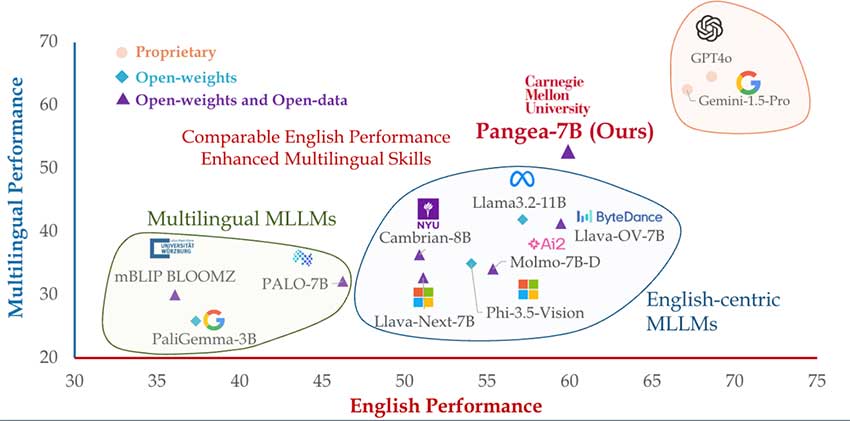
尽管多模态大型语言模型(MLLM)在英语上取得进展,但全球语言和文化的代表性仍不足。卡内基梅隆大学推出的PANGEA模型,使用包含39种语言的600万个样本的数据集PANGEAINS进行训练。评估结果显示,PANGEA在多语言任务上优于现有模型,并在多元文化理解方面表现突出。该模型的开源有望提升跨语言和文化的公平性与可访问性。
卡内基梅隆大学的“算法与大数据”课程由David Woodruff教授讲授,涵盖大数据算法如回归技术、子空间嵌入和分布式计算。课程结合理论与实践,适合研究生和高年级本科生。GetVM的Playground提供在线编程环境,帮助学生实践所学。
卡内基梅隆大学副教授Graham Neubig强调单智能体系统的重要性,指出多智能体系统存在结构匹配、信息传递和可维护性的问题。单智能体系统利用强大的语言模型和优化提示工程,能实现出色性能。在某些情况下,简单的单智能体系统可能更有效。
完成下面两步后,将自动完成登录并继续当前操作。