
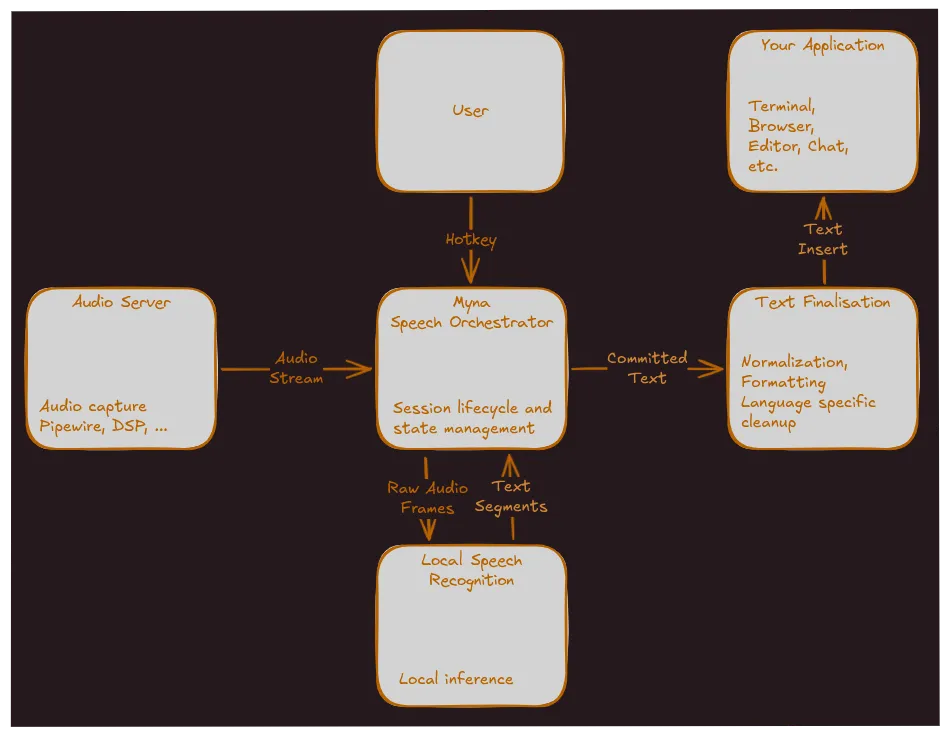
Myna发布,成为Ubuntu桌面系统的语音转文本解决方案
实时互动网
·

如何在自己的硬件上使用QVAC实现私有文本转语音
freeCodeCamp.org
·
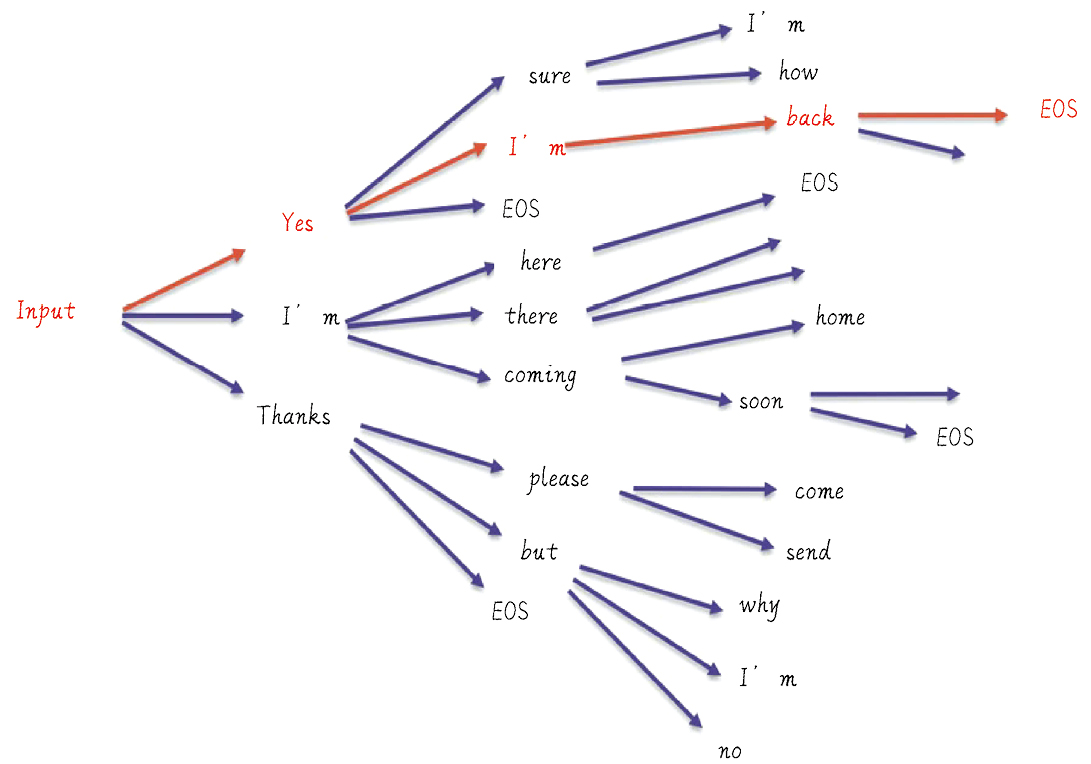
《GPT 图解》笔记:GPT-从 Decoder 到自回归文本生成
Ying’s Blog
·

使用Scikit-LLM进行多标签文本分类
MachineLearningMastery.com
·



Ubuntu 计划为所有文本字段添加 AI 语音输入功能
实时互动网
·
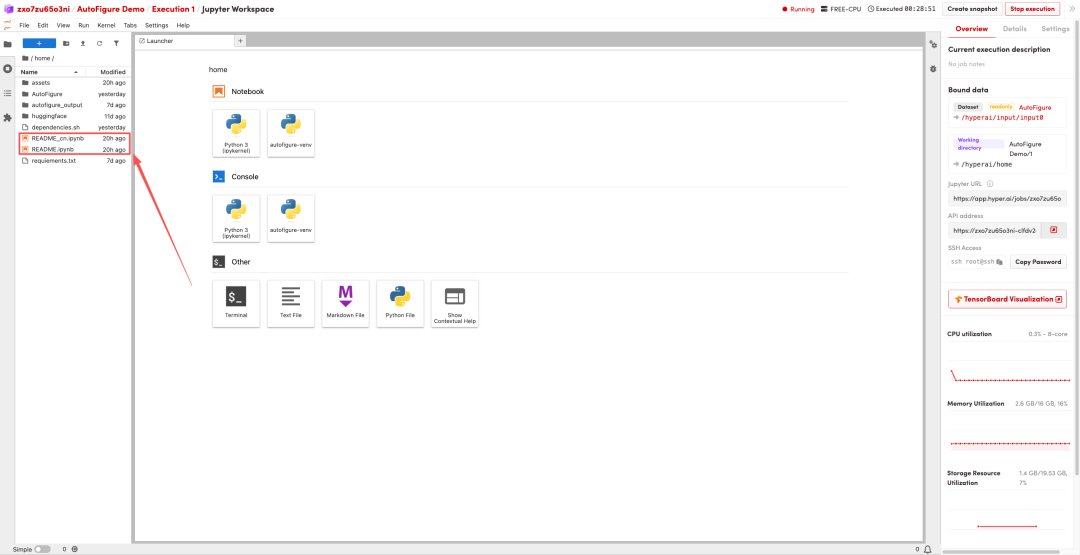
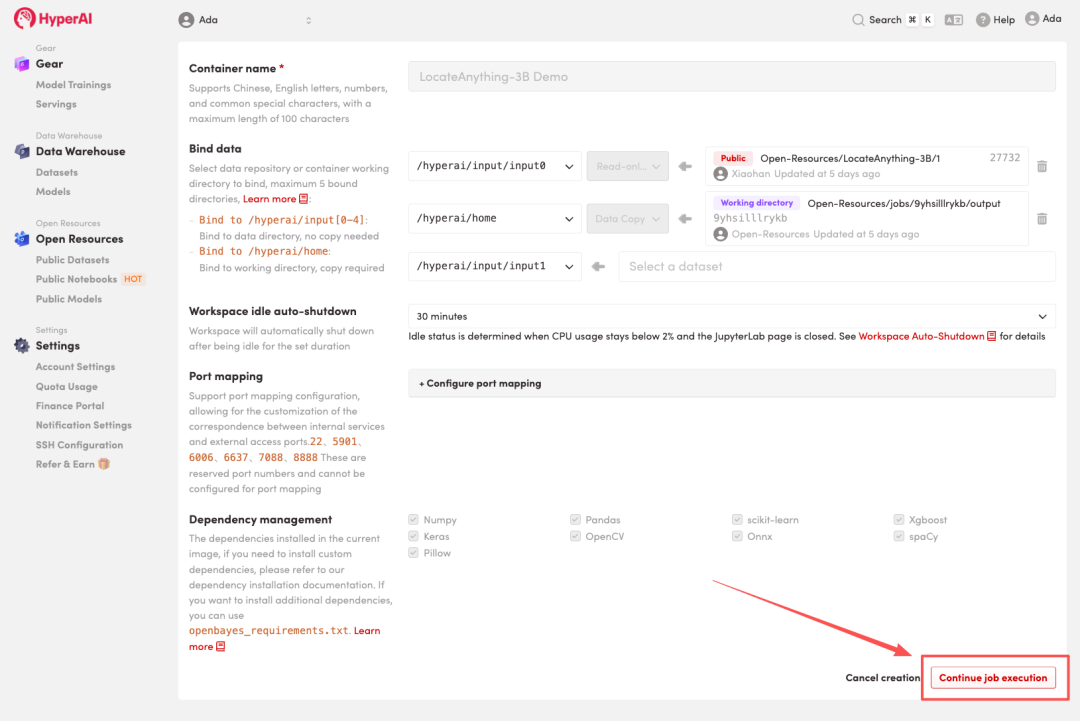
Free CPU教程丨西湖大学张岳团队开源科研插图神器AutoFigure,可精准理解长篇科学文本
HyperAI超神经
·

Scikit-LLM与传统文本分类器的比较:何时应使用LLM?
MachineLearningMastery.com
·


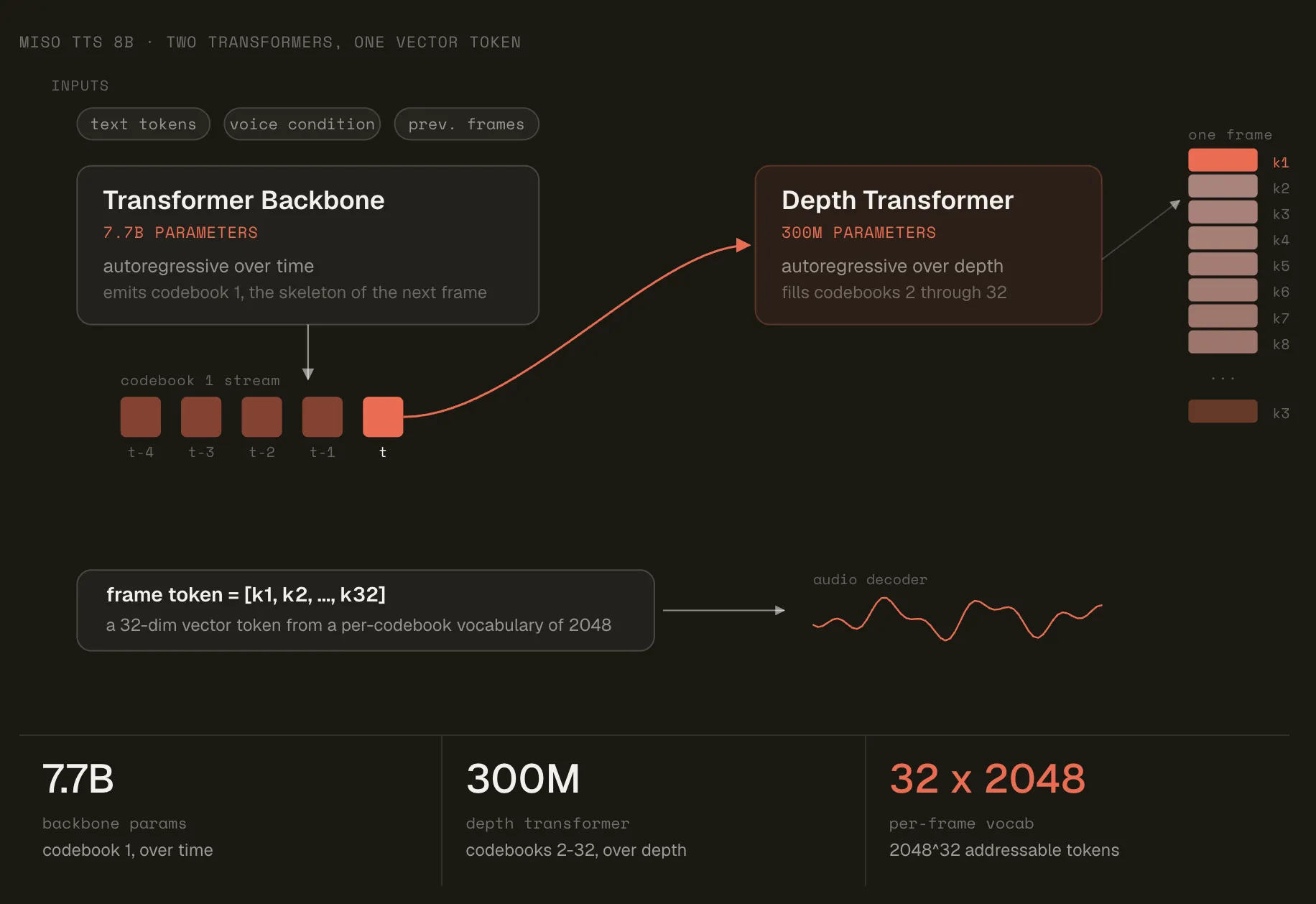
基于文本条件的JEPA用于学习语义丰富的视觉表示
Apple Machine Learning Research
·
