agentic-rag-for-dummies 是一个轻量级智能问答系统,支持对话记忆和多代理处理,提升交互自然度。它采用分层索引和模块化设计,集成 Gradio 界面,便于部署。awesome-claude 汇总了 Anthropic Claude AI 的资源,提供多语言 SDK 和云服务接入。cursor-talk-to-figma-mcp 实现了 Cursor AI 与 Figma 的双向交互和设计管理。eigent 是开源协同办公应用,支持多智能体协作,提升生产力。VoxCPM 是无分词文本到语音合成系统,专注自然语音生成。
EmoVoice模型基于大语言模型,解决了文本到语音(TTS)在情感表达控制方面的不足,实现了自然语言情感的精细控制,并通过并行输出音素和音频标记提高内容一致性,推动了情感语音合成的发展。
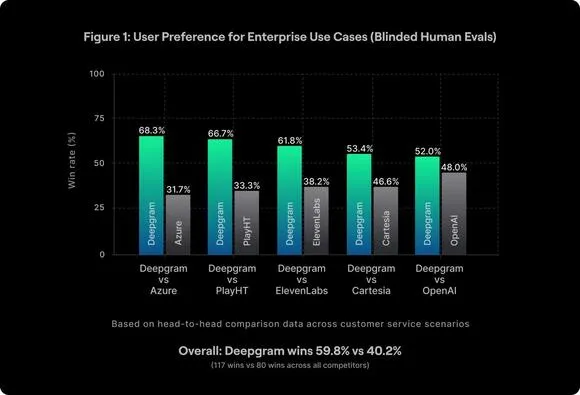
Deepgram推出了新一代文本到语音模型Aura-2,专为企业实时语音应用设计,提供清晰、低延迟的语音体验,支持行业术语精准发音,具备多种语音选择,优化企业沟通效率,降低成本。该平台可在云端或本地部署,确保安全性和灵活性。
本研究提出了一种基于检索增强生成的文本到语音合成框架,强调提示选择的重要性,能够动态调整语言风格,实现更自然的交流。
SlimSpeech是一种轻量高效的文本到语音合成系统,基于精简整流流。该研究通过优化模型结构和蒸馏技术,显著减少了模型参数,同时保持了与大型模型相当的合成效果。
本研究针对新手内容创作者在社交媒体视频中录制语音的困难,提出了一种新方法,通过用户提供的上下文简化文本到语音(TTS)生成,并利用SpeakEasy系统进行优化。研究结果表明,使用SpeakEasy的参与者能够更有效地生成符合个人标准的语音表现。
Spark-TTS是一种基于Qwen2.5大模型的先进文本到语音系统,支持中英文合成和零样本克隆。其特点包括高效流程、可控语音生成和双语支持。使用时需准备环境、安装依赖和下载模型,可通过命令行或Web UI进行合成。常见问题如依赖冲突和克隆效果不佳,已提供解决方案。
Ebook2Audiobook 是一款开源工具,能够将电子书转换为有声书,支持多种格式,方便用户在不同场景下使用文本到语音技术收听。
本研究提出了Llasa框架,解决了基于大语言模型的文本到语音系统在训练和推理阶段的计算能力扩展问题。实验结果表明,延长训练时间可以显著提升合成语音的自然性、复杂性和情感表现。
本文提出了一种轻量级的多语言文本到语音(TTS)模型,旨在解决北美三种土著语言(奥吉布瓦语、米克马克语和马利西特语)语音合成系统不足的问题,强调了多语言模型在数据稀缺情况下的优势。
本研究探讨了文本到语音(TTS)系统中外部工具生成的时长依赖问题,提出了一种新的对齐器训练方法,显著提高了对齐准确性,词错误率降低了16%,优化了TTS系统的自然度和可懂度。
本研究提出了Hard-Synth方法,利用大语言模型生成文本,并结合零样本文本到语音技术,解决了自动语音识别系统在文本数据稀缺时的标记成本问题。实验结果表明,该方法显著提升了Conformer模型的表现,降低了词错误率,提高了数据效率。
本研究针对文本到语音(TTS)评估中的一致性和稳健性问题,提出了改进的MUSHRA测试变体,以解决参考匹配偏差和评判模糊性。此外,研究发布了包含47,100个汉语和泰米尔语评分的MANGO数据集,旨在支持人类偏好分析和自动评估指标的开发。
本研究探讨了文本到语音系统中字母到音素转换的歧义问题,提出了一种基于大语言模型的上下文知识检索方法。实验结果表明,该方法显著提高了转换精确度,尤其在Librig2p数据集上降低了音素错误率。
本研究比较了自然语言翻译中的直接方法与传统叠加方法,发现两者性能差距消失。提出了综合层次系统以转移情感,并建立了基准测试集。研究探讨了不同发音对韵律转移的影响,提出多尺度、多模态的文本到语音系统以增强韵律表现。评估了预训练语言模型在文本转语音中的影响,发现迁移学习显著提高性能,对低资源语言模型建设具有重要意义。
本研究探讨了自回归变换器基础的文本到语音模型在处理未见长序列时的鲁棒性和长度泛化问题。提出了一种改进方法,通过对齐机制和相对位置信息增强,提升输出的自然性和表达力,解决了重复或丢失单词的问题。
本文介绍了多种非自回归文本到语音(TTS)模型的创新,包括VARA-TTS、Diff-TTS和NAST-S2X。VARA-TTS通过多层注意力机制提高推理速度和语音质量,Diff-TTS显著提升合成速度,NAST-S2X实现高质量的同时口译。这些模型在推理效率和语音合成质量上均有显著进展。
本文研究了在低资源环境下提高自动语音识别(ASR)和语音翻译性能的方法。通过预训练声学模型和结合文本到语音(TTS)技术,利用少量数据实现了显著的性能提升。同时,探讨了文本多样性和合成数据对ASR性能的影响,并提出了有效的模型优化策略。
本研究探讨了低资源环境中自动语音识别(ASR)性能不足的问题,提出利用强大的文本到语音(TTS)模型进行数据增强的方法。实验结果表明,文本多样性、说话人多样性及合成数据量是提升ASR性能的关键因素,尤其是文本多样性对性能的影响显著。
本研究提出EmoKnob框架,解决了文本到语音技术中情感选择和强度控制的问题。EmoKnob通过少量示例实现细粒度情感控制,并引入评估指标系统性评估情感合成效果。结果显示,该框架在情感表现力上优于商业TTS服务。
完成下面两步后,将自动完成登录并继续当前操作。