
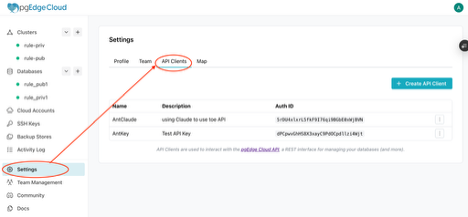
Antony Pegg:如何通过API在pgEdge Cloud上构建RAG服务器
Planet PostgreSQL
·

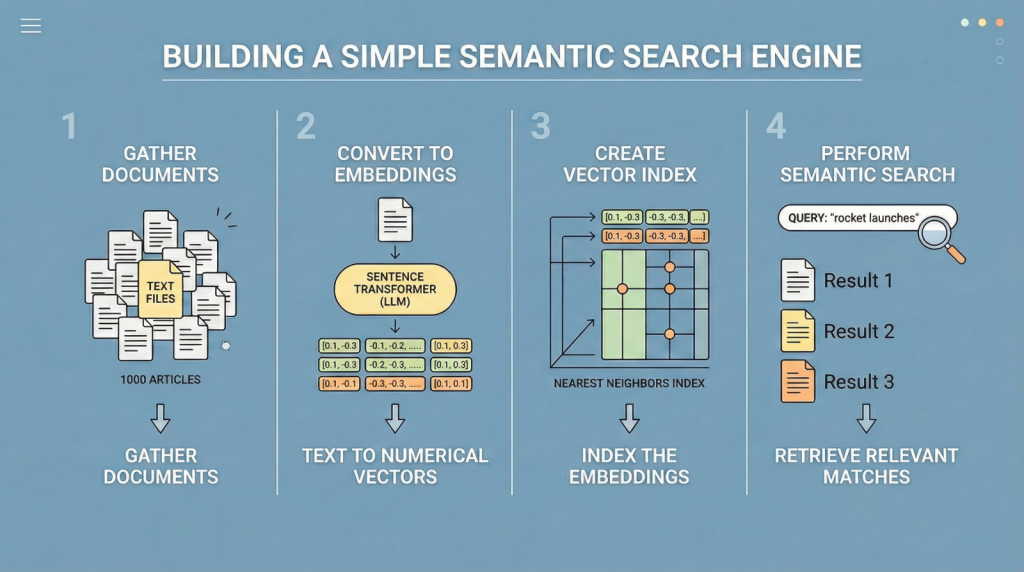
利用LLM嵌入构建语义搜索
MachineLearningMastery.com
·

Voyage 4模型系列:采用混合专家架构的共享嵌入空间
Voyage AI
·
10种在表格机器学习任务中使用嵌入的方法
MachineLearningMastery.com
·

MANZANO:一个简单且可扩展的统一多模态模型,采用混合视觉标记器
Apple Machine Learning Research
·

利用LLM嵌入进行文本数据的7个高级特征工程技巧
MachineLearningMastery.com
·
Qwen3 Embedding 技术解析:多语言文本嵌入与重排序的新标杆
我爱自然语言处理
·

如何利用文本嵌入构建索引
DEV Community
·

个性化图像:自回归模型在新研究中与扩散模型相媲美
DEV Community
·

文本嵌入的长度偏见及其在搜索中的影响
Jina AI
·

汉斯-尤尔根·肖宁:pgai:将维基百科导入PostgreSQL
Planet PostgreSQL
·

文本嵌入的示例应用
MachineLearningMastery.com
·

使用变换器生成文本嵌入
MachineLearningMastery.com
·
