
利用LLM嵌入构建语义搜索
内容提要
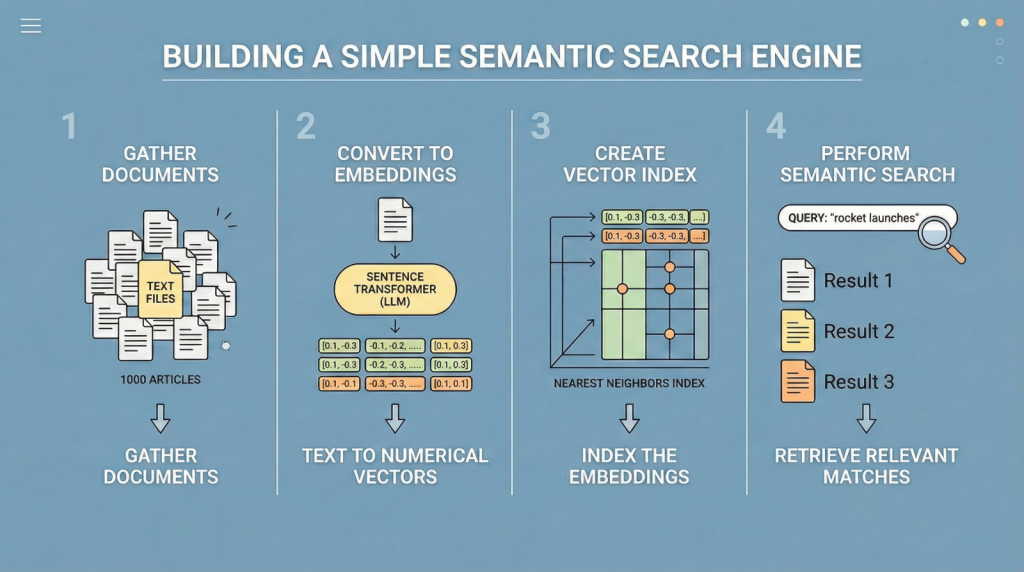
本文介绍了如何利用句子嵌入和最近邻算法构建语义搜索引擎。与传统关键词搜索相比,语义搜索能够更好地捕捉文本的意义。文章提供了使用Python实现语义搜索的步骤,包括数据集加载、嵌入生成和最近邻搜索,最终展示了如何根据查询返回相似文档。
关键要点
-
传统搜索引擎依赖关键词搜索,存在局限性,无法捕捉同义词和语义细微差别。
-
语义搜索通过关注文本的意义而非确切措辞来解决传统搜索的局限性。
-
大型语言模型(LLMs)将文本转换为数值向量表示,称为嵌入,能够编码文本的语义信息。
-
使用Python实现语义搜索的步骤包括数据集加载、嵌入生成和最近邻搜索。
-
通过最近邻算法,搜索引擎能够找到与查询最相似的文档,使用余弦距离来衡量相似性。
-
构建的语义搜索引擎可以作为现代检索增强生成系统的基础层。
延伸解读
语义搜索的优势
与传统的关键词搜索相比,语义搜索能够更好地理解文本的含义,避免了因词汇差异而导致的相关信息遗漏。这种方法特别适合处理同义词和语义细微差别,使得用户能够获得更准确的搜索结果。
构建语义搜索引擎的步骤
文章详细介绍了使用Python构建语义搜索引擎的具体步骤,包括数据集加载、嵌入生成和最近邻搜索。这些步骤为开发者提供了清晰的实现路径,适合初学者学习和实践。
潜在的局限性
尽管语义搜索在捕捉文本意义方面表现优越,但仍然存在一些局限性。例如,模型的性能依赖于训练数据的质量和多样性,若数据不足或偏颇,可能导致搜索结果不准确。
延伸问答
什么是语义搜索,它与传统搜索有什么不同?
语义搜索关注文本的意义而非确切措辞,能够捕捉同义词和语义细微差别,解决了传统关键词搜索的局限性。
如何使用Python构建语义搜索引擎?
构建语义搜索引擎的步骤包括数据集加载、生成文本嵌入和实现最近邻搜索。
大型语言模型在语义搜索中起什么作用?
大型语言模型将文本转换为数值向量表示,称为嵌入,能够编码文本的语义信息。
最近邻算法是如何在语义搜索中应用的?
最近邻算法通过计算嵌入向量之间的余弦距离,找到与查询最相似的文档。
语义搜索引擎的构建可以用于哪些现代系统?
构建的语义搜索引擎可以作为现代检索增强生成系统的基础层。
如何评估语义搜索的结果相似性?
通过计算余弦距离来衡量相似性,距离越小表示相似性越高。
