

使用Transformers.js和句子嵌入构建语义搜索
MachineLearningMastery.com
·
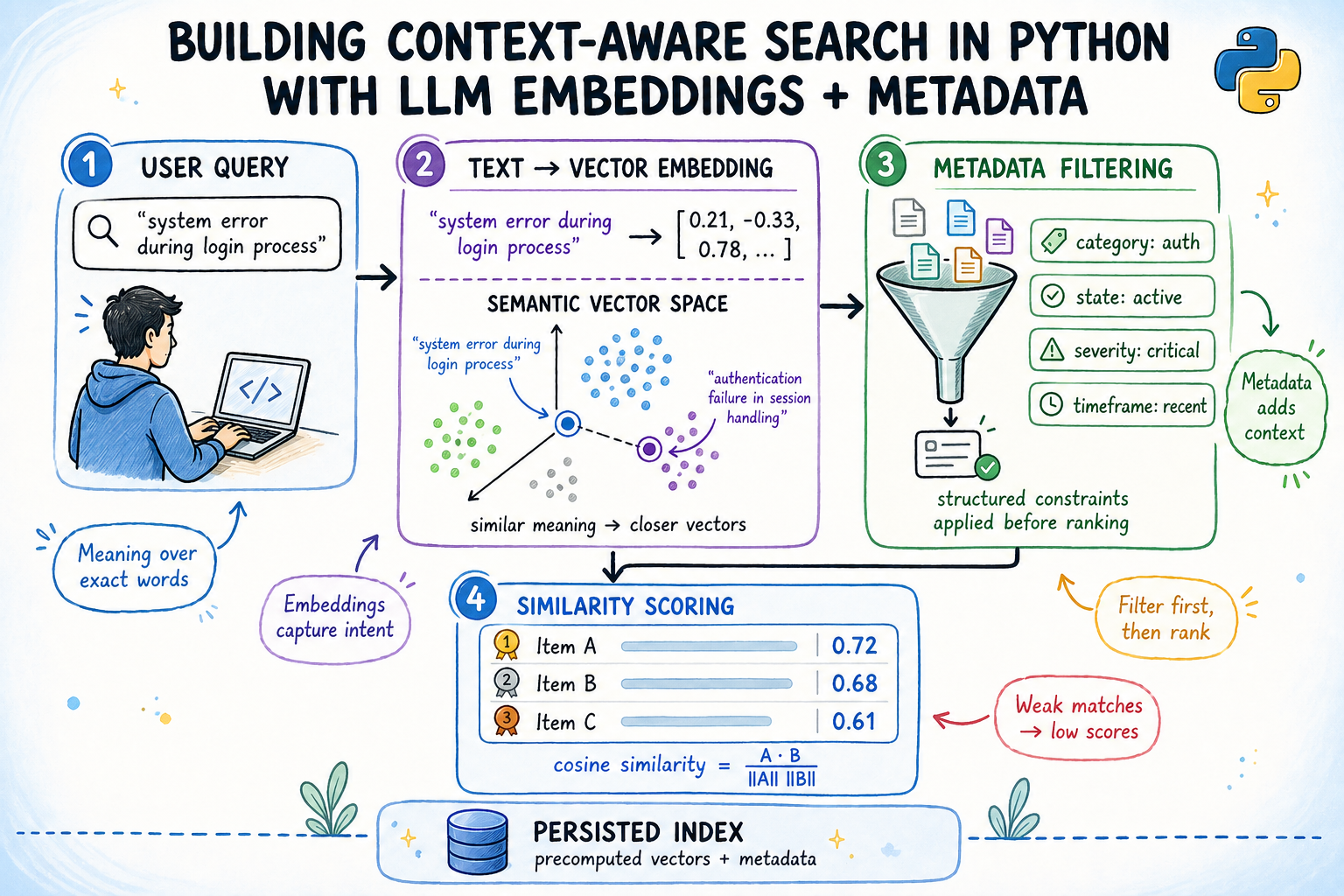
使用LLM嵌入和元数据构建上下文感知的Python搜索
MachineLearningMastery.com
·
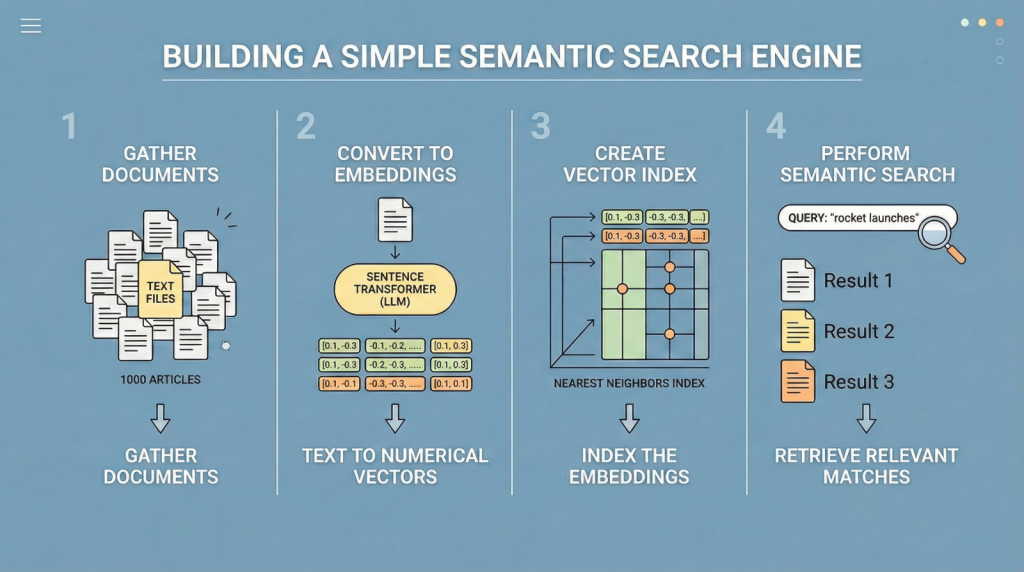
利用LLM嵌入构建语义搜索
MachineLearningMastery.com
·

为什么以及何时使用句子嵌入而非词嵌入
MachineLearningMastery.com
·

DeepResearch中多样化查询生成的次模优化
Jina AI
·

超越单词:掌握句子嵌入在语义自然语言处理中的应用
DEV Community
·

Meta开源大型概念模型,一种能够预测完整句子的语言模型
InfoQ
·

基于症状的诊断系统构建:使用all-MiniLM-L6-V2
DEV Community
·

