
使用LLM嵌入和元数据构建上下文感知的Python搜索
内容提要
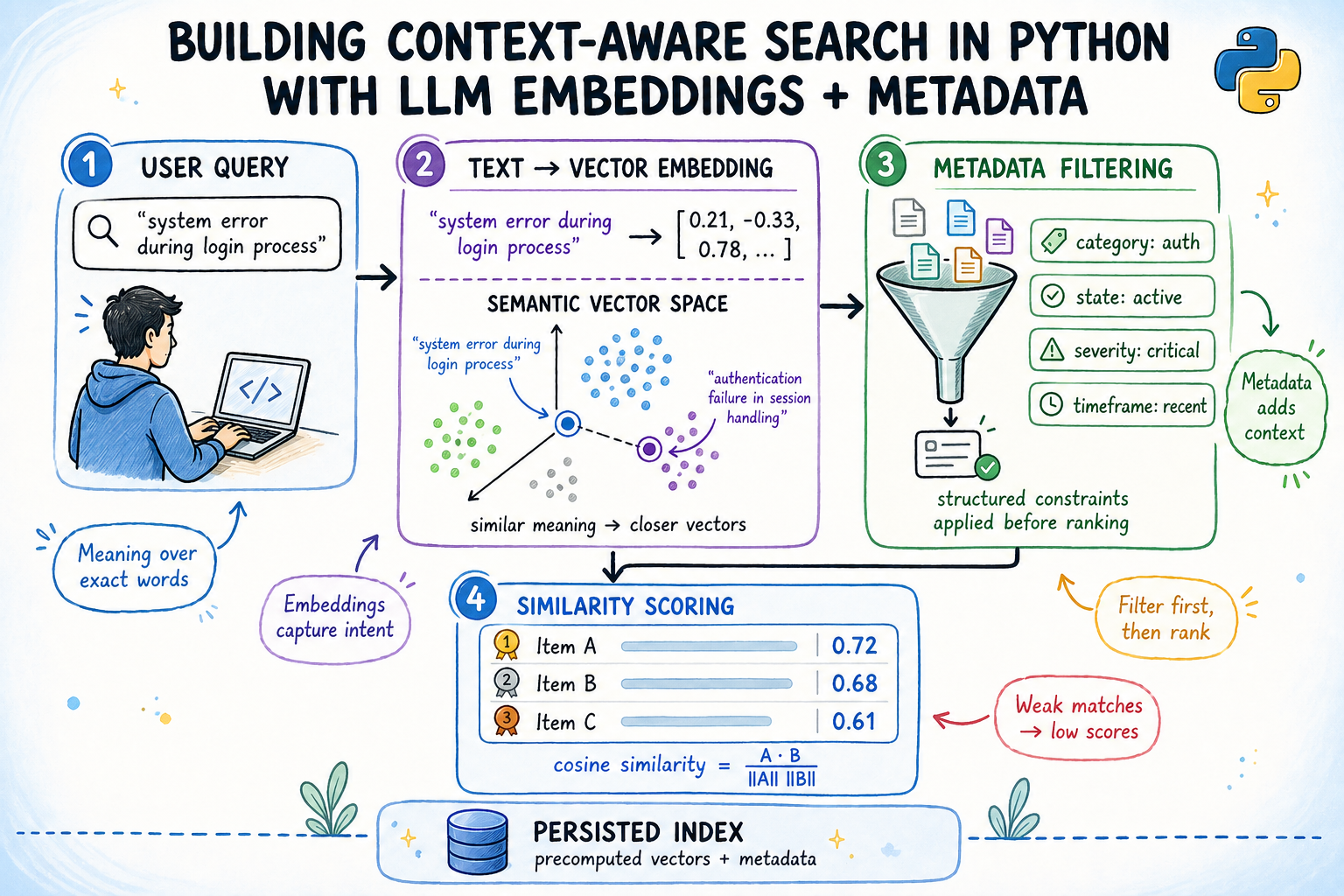
本文介绍了如何使用Python构建上下文感知的语义搜索引擎,结合嵌入式相似性和结构化元数据过滤。内容涵盖句子嵌入和余弦相似度的原理,构建元数据感知的搜索索引,以及索引的持久化方法。这些技术能够有效找到与用户查询相关的文档,同时考虑上下文约束。
关键要点
-
本文介绍如何使用Python构建上下文感知的语义搜索引擎,结合嵌入式相似性和结构化元数据过滤。
-
语义搜索通过将文本转换为密集的向量表示来解决关键词搜索的局限性,利用余弦相似度来衡量向量之间的相似性。
-
构建元数据感知的搜索索引,能够根据团队、状态、优先级和日期等条件进行过滤。
-
索引的持久化方法确保嵌入只计算一次,并在后续运行中高效加载。
-
使用句子嵌入模型生成384维的向量表示,支持无API密钥的本地计算。
-
在搜索过程中,首先进行过滤,然后再进行评分,以提高效率和准确性。
-
支持多种查询,包括不带过滤的语义搜索、带状态和日期过滤的查询,以及跨团队的优先级过滤查询。
-
通过将嵌入矩阵和元数据保存到磁盘,实现索引的持久化,避免每次启动时重新编码。
延伸解读
语义搜索的优势与局限
语义搜索通过将文本转换为向量表示,能够更好地理解用户查询的意图,超越传统关键词搜索的局限。然而,语义模型的效果依赖于训练数据的质量和多样性,可能在特定领域或专业术语上表现不佳。用户在使用时需注意这些潜在的局限性。
元数据过滤的重要性
在构建上下文感知的搜索引擎时,元数据过滤是提升搜索准确性的关键。通过在评分前进行过滤,可以有效减少无关结果,提高系统的响应速度和用户体验。尤其在处理大量文档时,合理的元数据设计能显著提升搜索效率。
索引持久化的实践意义
索引的持久化方法确保了在后续运行中无需重复计算嵌入,节省了计算资源和时间。这种设计对于需要频繁查询的应用场景尤为重要,能够显著提升系统的整体性能和用户满意度。
延伸问答
如何使用Python构建上下文感知的语义搜索引擎?
可以通过结合嵌入式相似性和结构化元数据过滤来构建上下文感知的语义搜索引擎。
什么是句子嵌入模型,它是如何工作的?
句子嵌入模型将字符串转换为固定长度的向量,语义相似的句子会生成指向相似方向的向量。
如何实现元数据感知的搜索索引?
通过将元数据与嵌入矩阵结合,可以根据团队、状态、优先级和日期等条件进行过滤,构建搜索索引。
为什么在搜索过程中先进行过滤再评分?
先过滤可以避免对不相关文档进行评分,从而提高效率并减少计算资源浪费。
如何持久化搜索索引以提高效率?
通过将嵌入矩阵和元数据保存到磁盘,可以避免每次启动时重新编码,提高加载效率。
可以使用哪些查询类型进行搜索?
支持不带过滤的语义搜索、带状态和日期过滤的查询,以及跨团队的优先级过滤查询。
