

向量嵌入解析:从理论到实际应用
Redis Blog
·

通过Managed Weaviate加速扩展:现已在DigitalOcean公开预览
The DigitalOcean Blog
·

什么是向量搜索?
Databricks
·

使用Transformers.js和句子嵌入构建语义搜索
MachineLearningMastery.com
·
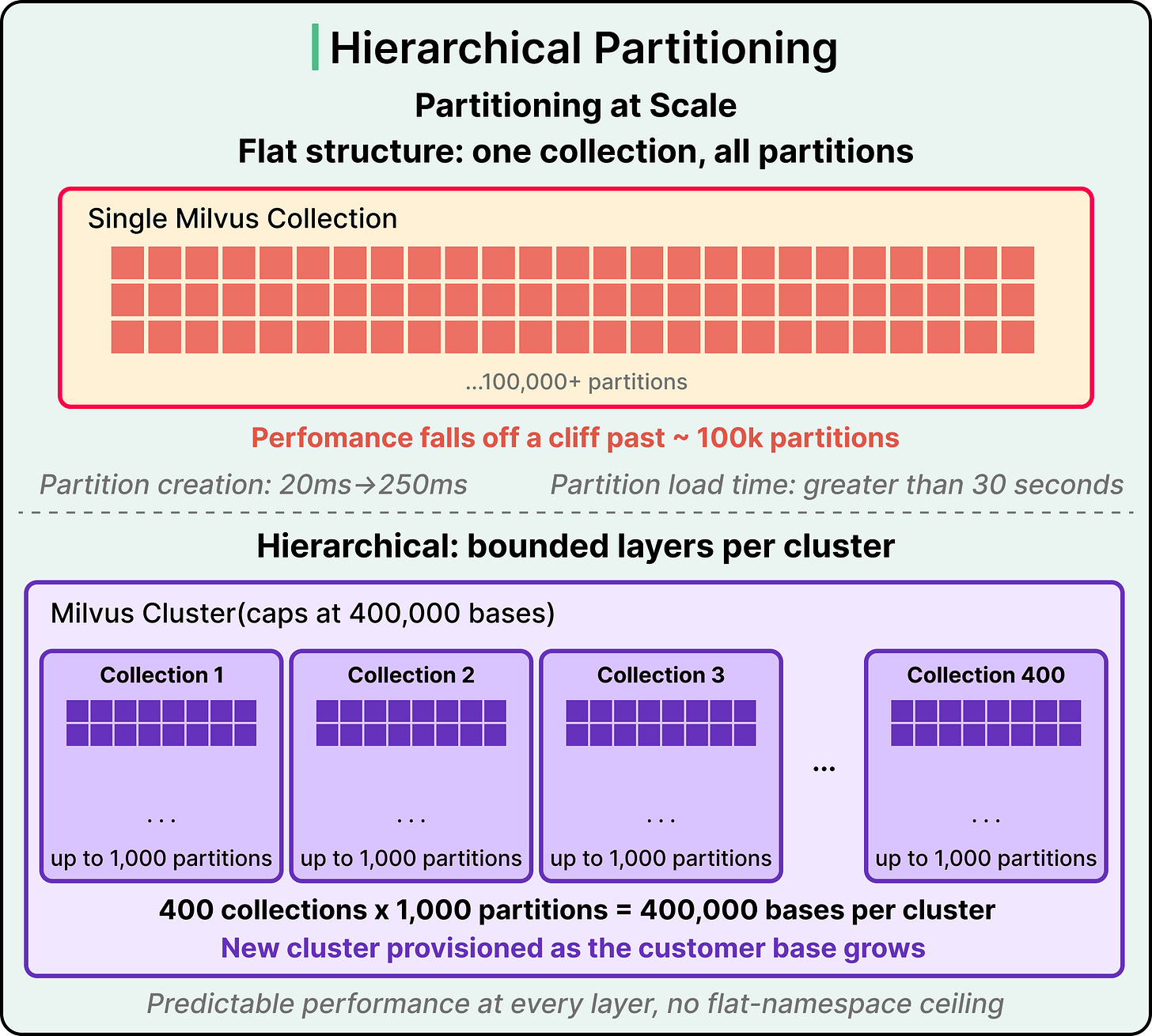
Airtable如何构建其AI功能背后的搜索层
ByteByteGo Newsletter
·

在RAG中实现混合语义-词汇搜索
MachineLearningMastery.com
·
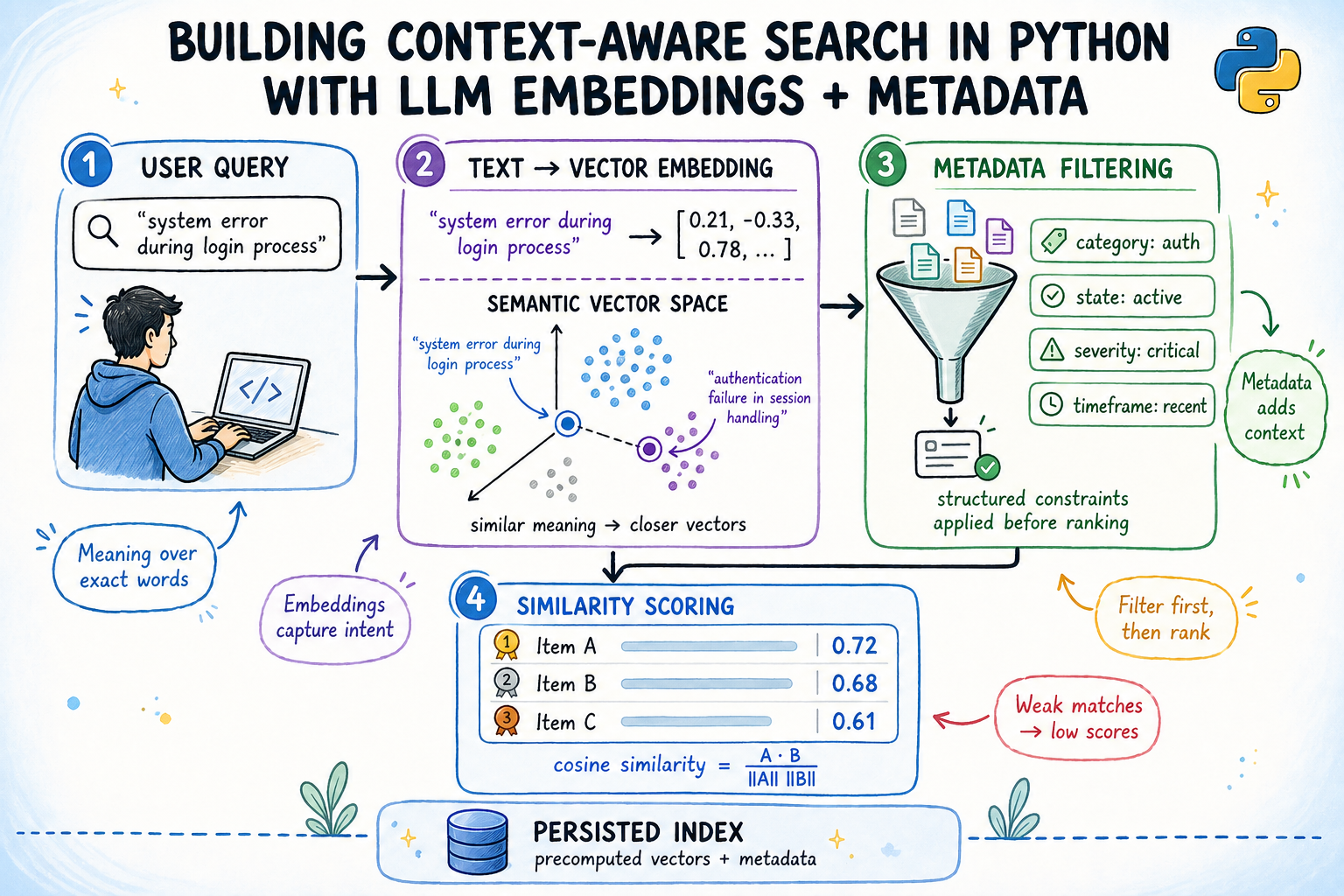
使用LLM嵌入和元数据构建上下文感知的Python搜索
MachineLearningMastery.com
·

你所说的语义搜索究竟是什么意思?
Stack Overflow Blog
·

什么是pgvector?
Databricks
·

Ahsan Hadi:pgEdge Vectorizer和RAG服务器:将语义搜索引入PostgreSQL(第二部分)
Planet PostgreSQL
·

设计解耦:亿级向量搜索
Databricks
·

Redis中的向量索引:算法、混合搜索与扩展
Redis Blog
·

大型语言模型、乐高和LED灯:一位Elastic工程师如何保持活力并以好奇心引领创新
Elastic Blog - Elasticsearch, Kibana, and ELK Stack
·

向量数据库与传统数据库:有什么区别?
Redis Blog
·
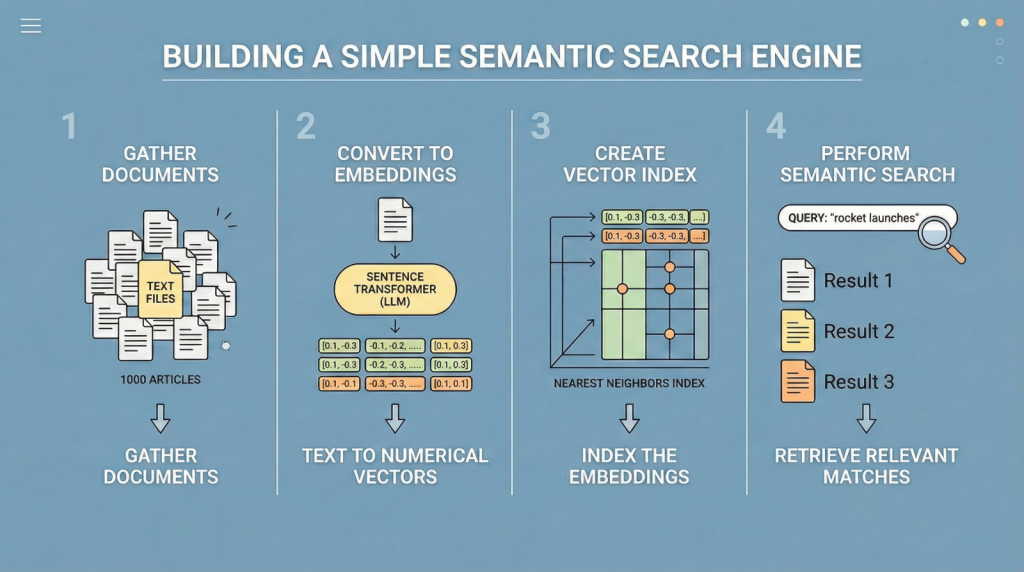
利用LLM嵌入构建语义搜索
MachineLearningMastery.com
·
向量数据库面临的最常见挑战是什么?
Redis Blog
·

即使是生成式人工智能也使用维基百科作为来源
Stack Overflow Blog
·

Ramp如何在Vercel上通过100倍流量激增保持100%正常运行
Vercel News
·
