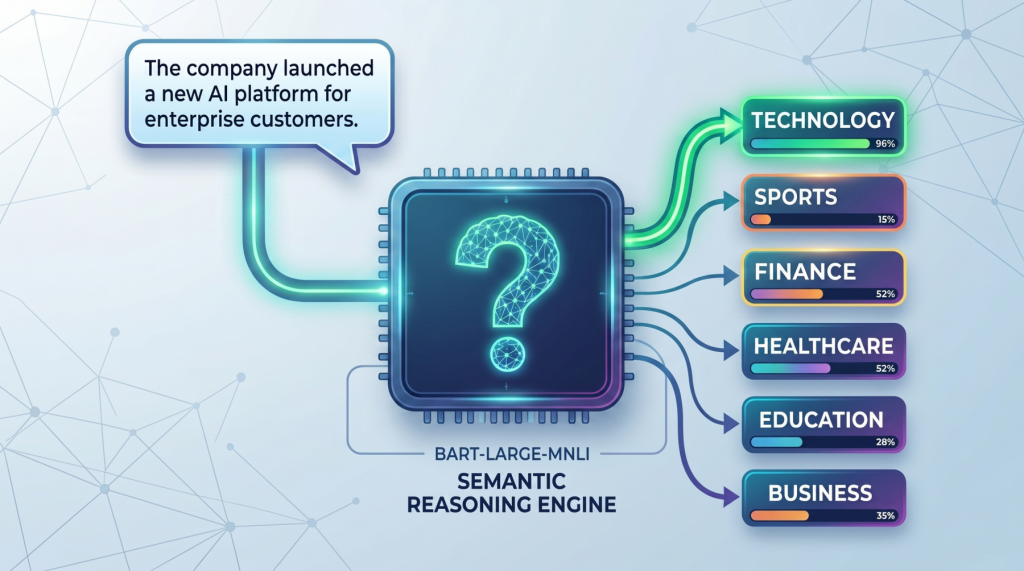
零样本文本分类是一种无需特定任务训练数据即可标记文本的方法。模型通过将标签转化为自然语言陈述,判断输入文本与这些陈述的匹配程度。这种方法适用于快速原型开发和资源有限的任务。使用预训练模型(如facebook/bart-large-mnli)可以有效进行多标签分类和自定义假设模板,从而提高分类准确性,关键在于清晰的标签定义和合理的假设模板。
完成下面两步后,将自动完成登录并继续当前操作。