
零样本文本分类入门
内容提要
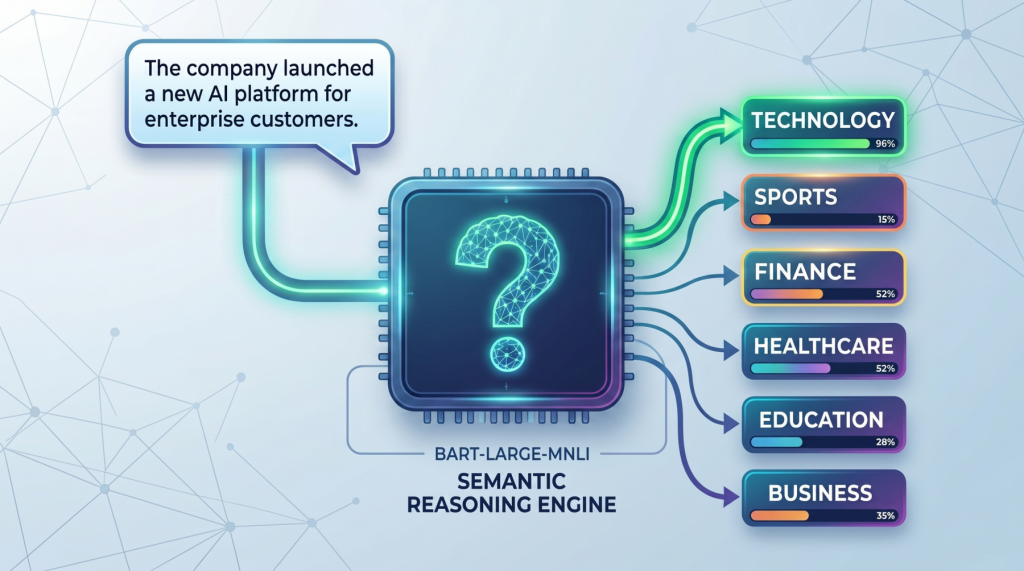
零样本文本分类是一种无需特定任务训练数据即可标记文本的方法。模型通过将标签转化为自然语言陈述,判断输入文本与这些陈述的匹配程度。这种方法适用于快速原型开发和资源有限的任务。使用预训练模型(如facebook/bart-large-mnli)可以有效进行多标签分类和自定义假设模板,从而提高分类准确性,关键在于清晰的标签定义和合理的假设模板。
关键要点
-
零样本文本分类是一种无需特定任务训练数据即可标记文本的方法。
-
模型通过将标签转化为自然语言陈述,判断输入文本与这些陈述的匹配程度。
-
这种方法适用于快速原型开发和资源有限的任务。
-
使用预训练模型(如facebook/bart-large-mnli)可以有效进行多标签分类和自定义假设模板。
-
清晰的标签定义和合理的假设模板是提高分类准确性的关键。
延伸解读
零样本分类的应用场景
零样本文本分类特别适合快速原型开发和资源有限的任务。它可以在没有特定训练数据的情况下,快速对文本进行标记,适用于客户服务、内容标记和用户意图检测等场景。这种灵活性使得企业能够在不投入大量资源的情况下,测试和验证新想法。
标签定义的重要性
在零样本分类中,标签的清晰定义至关重要。模糊的标签可能导致模型理解偏差,从而影响分类准确性。使用具体且语义明确的标签,如“账单问题”而非“钱”,可以显著提高模型的表现。因此,在设计标签时,需考虑其语义清晰度。
假设模板的优化
自定义假设模板可以有效提升零样本分类的结果。通过调整模板,使其更符合实际任务的需求,模型能够更准确地判断文本与标签的匹配程度。选择合适的模板不仅能提高分类准确性,还能增强模型的推理能力。
延伸问答
什么是零样本文本分类?
零样本文本分类是一种无需特定任务训练数据即可标记文本的方法。
零样本文本分类的工作原理是什么?
模型将标签转化为自然语言陈述,判断输入文本与这些陈述的匹配程度。
零样本文本分类适合哪些场景?
适用于快速原型开发和资源有限的任务,如路由支持票、标记文章等。
如何提高零样本文本分类的准确性?
清晰的标签定义和合理的假设模板是提高分类准确性的关键。
使用预训练模型进行零样本文本分类的优势是什么?
使用预训练模型可以有效进行多标签分类和自定义假设模板,提高分类效果。
如何使用facebook/bart-large-mnli进行零样本文本分类?
可以通过加载零样本分类管道并输入文本和候选标签来使用该模型。
