本文介绍了如何使用scikit-LLM库进行多标签文本分类,利用大型语言模型(LLM)进行零-shot推理,无需标记训练数据。文章阐述了多标签分类的定义及其重要性,配置scikit-LLM的方法,以及如何加载真实数据集进行情感预测。通过示例,展示了为文本分配多个情感标签的简便性和高效性。
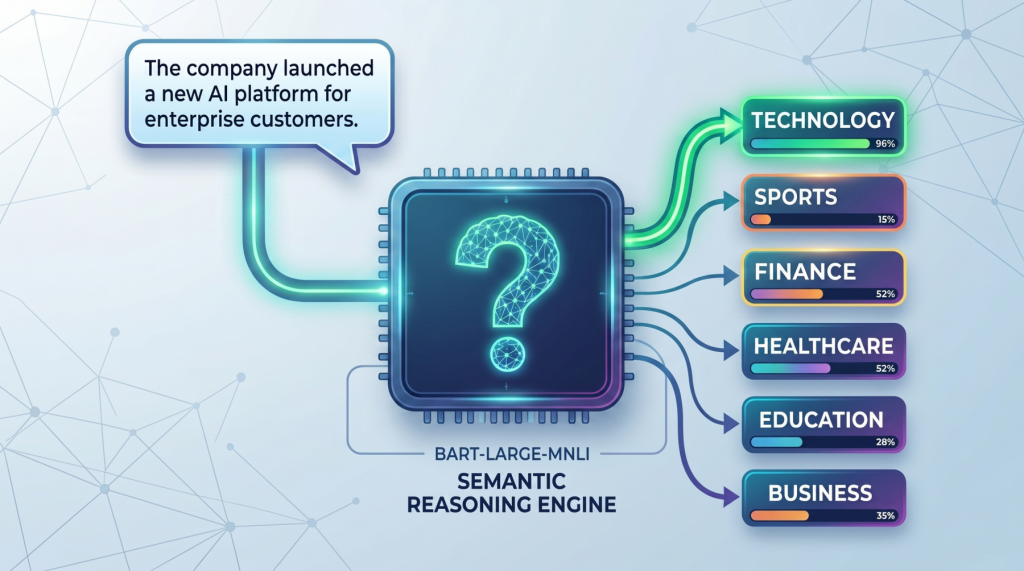
零样本文本分类是一种无需特定任务训练数据即可标记文本的方法。模型通过将标签转化为自然语言陈述,判断输入文本与这些陈述的匹配程度。这种方法适用于快速原型开发和资源有限的任务。使用预训练模型(如facebook/bart-large-mnli)可以有效进行多标签分类和自定义假设模板,从而提高分类准确性,关键在于清晰的标签定义和合理的假设模板。
本研究提出了FairPO框架,通过优化偏好信号提升多标签分类的公平性。结果表明,该框架有效减少标签间的偏见,确保不同标签类别的公平对待,并具备扩展到多标签生成的潜力。
本研究探讨了地球观测中复杂数据的不确定性感知,提出了一种评估框架,展示了预训练数据在多标签分类和分割任务中的强泛化能力,为未来研究提供新视角。
本研究探讨了多标签分类中的标签噪声问题,提出了一种新的后纠正方法,利用深度生成技术建模标签噪声。结果表明,该方法在多种噪声标签设置下有效提高了预测准确性,优于现有方法。
本研究提出了一种新颖的多标签分类系统,利用聊天助手对话数据,满足焦虑和抑郁症早期检测的需求。结合大型语言模型和机器学习,系统准确率达到90%,显著提升了现有检测效果。
AIxiv专栏促进学术交流,报道超过2000篇研究。KDD 2025将在多伦多举行,阿里与浙江大学合作的研究成果被收录,提出了针对多标签分类的图神经网络增强技术CorGCN,有效解决模糊特征和拓扑问题,提升节点分类能力。
多标签分类在计算机视觉中应用广泛,适合复杂场景,能够同时预测多个类别。与目标检测相比,其计算复杂度低、推理速度快、标注成本低且鲁棒性高。PaddleX提供多种模型,支持简单的Python API,便于快速体验和二次开发。
本研究提出了一种双层对比学习框架,解决了多视角多标签分类中的视角和标签不完整问题。该方法在多个基准数据集上优于现有技术。
本研究提出了一种新方法RR2QC,旨在提高在线教育中多标签问题分类的准确性。该方法通过利用标签语义和元标签细化,显著增强了对长尾标签的理解和预测能力,从而改善个性化学习和资源推荐效果。
本研究提出了AttentionXML模型,利用多标签注意机制和概率标签树,解决极端多标签文本分类问题,表现优于传统方法。此外,HAXMLNet、LAHA和CascadeXML等新模型在处理大规模标签集和少样本分类任务中也取得了显著进展。
本文提出了一个统一的异构学习框架,结合加权无监督和有监督对比损失,以解决对比学习中的假阴性问题。实验结果显示,该方法在复杂数据模拟中表现优异,显著提升了无监督学习的泛化性能和准确性。此外,研究还探讨了多标签多分类任务中的对比损失,并提出新算法以提高分类准确率。
本文提出了多种新方法解决多标签分类中的噪声标签和类别不平衡问题,包括统一蒸馏框架、分布平衡损失函数和正例与未标注多标签分类(PU-MLC)。实验证明这些方法在新创建的数据集上具有更高的有效性和鲁棒性,推动了多标签学习的研究进展。
本文介绍了一种基于分层结构的深度卷积神经网络(HD-CNNs),通过粗细分类器提高分类效果,并在CIFAR100和ImageNet上取得优异成绩。此外,提出了自适应分层网络、多标签分类模型及长文本分类方法,显著提升了分类性能和效率。
该研究提出了一种基于深度卷积神经网络的多标签分类框架,能够预测14种胸部疾病的风险,并引入标签平滑技术处理不确定样本。模型在超过20万的数据集上训练,平均AUC分数达到0.940,优于多位医学专家。此外,研究还探索了多实例学习和广义零样学习等方法,提升了胸部X射线图像的分类和定位能力。
本文介绍了DRUM方法,通过双向RNN挖掘知识图谱中的逻辑规则,实现链路预测。结合神经符号AI,提出多种基于规则的知识图谱构建方法,提升模型的精度和可解释性。同时,研究了神经符号技术在多标签分类中的应用,提出新的推理方法,展示其在准确性和资源使用上的优势。
本文介绍了多种对比学习方法的研究进展,包括新算法CLAE、基于标签锚定的LaCon和联合对比学习JCL等。这些方法通过数据增强、参数优化和结合不同数据源,显著提升了自监督学习和多标签分类任务的性能,展示了对比学习在计算机视觉和自然语言处理等领域的广泛应用潜力。
本文介绍了参与 YouTube-8M 视频理解挑战的经历与成果,采用多剪辑集成方法取得前十名的成绩,并探讨了多标签视频分类的潜力及未来研究方向。
本文提出了一种多 verbalizer 框架的层级文本分类方法,旨在解决少样本低资源问题,显著提升分类性能。研究还介绍了分层感知提示调节方法(HPT)和深度强化学习策略,在多标签文本分类中取得了先进表现。此外,探索了自我监督学习和对抗框架在层次分类中的应用,提出了新的学习范式和文本生成框架,展示了优越的实验结果。
本研究探讨了通过部分标签训练神经网络来解决多标签分类中的标签不平衡问题,提出了伪标注技术、新损失函数和动态训练方案。实验结果表明,该方法在多个数据集上优于现有技术,尤其在部分标注情况下表现突出。
完成下面两步后,将自动完成登录并继续当前操作。