

使用Scikit-LLM构建端到端情感分析管道
MachineLearningMastery.com
·
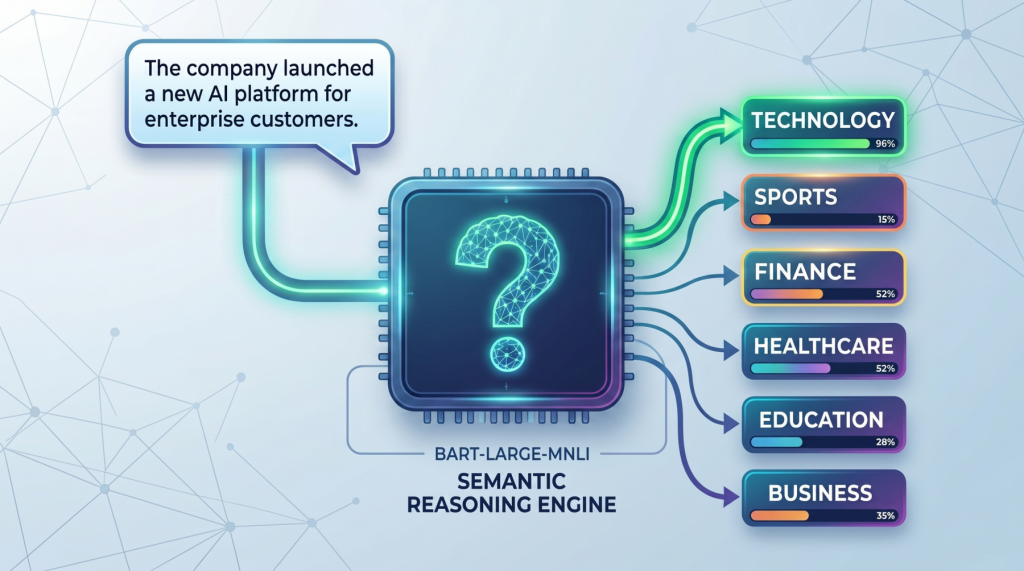
零样本文本分类入门
MachineLearningMastery.com
·

EMBridge:通过跨模态表示学习提升肌电信号的手势泛化能力
Apple Machine Learning Research
·

CPEP:对比姿态-肌电预训练提升基于肌电信号的手势泛化能力
Apple Machine Learning Research
·

使用Scikit-LLM进行零样本和少样本分类
MachineLearningMastery.com
·

Jina分类器API:高性能零样本和少样本分类
Jina AI
·
