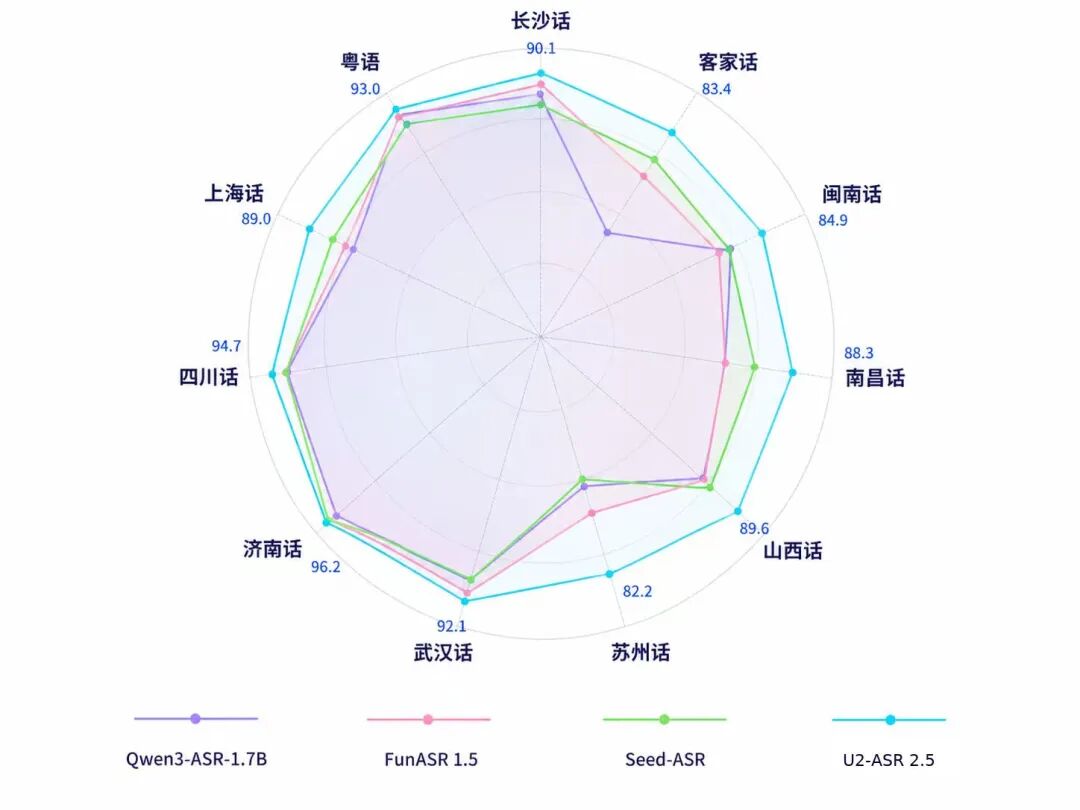
云知声推出的U2-ASR 2.5方言语音识别模型支持100种以上方言,识别准确率超过90%。该模型通过优化数据处理、解码和语义理解,将方言转化为规范普通话,广泛应用于政务、医疗和客服等领域。
本文提出了一种新方法,通过量化低秩适配(QLoRA)对4GB显存系统进行阿拉伯语言处理的Qwen2-1.5B模型微调,解决了阿拉伯自然语言处理中的形态复杂性和方言变异问题。实验结果表明,该模型在文本分类、问答和方言识别等任务上性能显著提升,最终损失收敛至0.1083,为低资源语言适配和大规模语言模型的高效微调提供了重要贡献。
本研究探讨了西班牙方言中共同实例的分类困难,提出通过动态训练自动检测共同实例,以提高方言识别模型的准确性和公平性。研究引入了带有共同实例注释的古巴西班牙方言数据集,首次关注加勒比地区方言识别。
本文探讨南亚语言技术中的数据散布问题,强调研究语言历史的重要性,并提出新策略以打破数据壁垒。介绍了多语言大型模型的进展,特别是在濒危语言的机器翻译和方言识别方面,旨在促进语言保护与多样性。
本文研究了阿拉伯语方言识别的方法,利用语音识别系统的音位和声学特征,结合多类支持向量机(SVM),在现代标准阿拉伯语与方言之间实现了100%的准确率。研究还探讨了五种主要方言的识别,准确率为52%。此外,文章分析了方言识别中的错误模式,并发布了相关数据集供研究使用。
2024年8月22日,ChatGPT语音模式内测,测试了英语学习、方言识别、多角色对话、音乐识别与创作、情感识别与表达、创意生成六个方面。发现ChatGPT在语言学习方面灵活,粤语表现完美但上海话有些尴尬,能模仿多种角色但无法真正理解说话者身份,对音乐相关内容拒绝强烈,情感表达过于相似却不够真实,与Claude对轰后ChatGPT被认为是捧哏角色。
本文研究自监督语音表示的特征空间分布,提出了一种新的说话者标准化方法,有效消除语音中的说话者信息。通过主成分分析,探讨不同层如何编码声学参数,并提出基于子空间的学习机制,应用于语言验证和方言识别。同时,研究无监督声学特征在语音识别中的应用,提升元音分类的准确性。
完成下面两步后,将自动完成登录并继续当前操作。