
云知声 U2-ASR 2.5上线:覆盖七大方言体系,支持100种以上方言及地方口音识别转写
内容提要
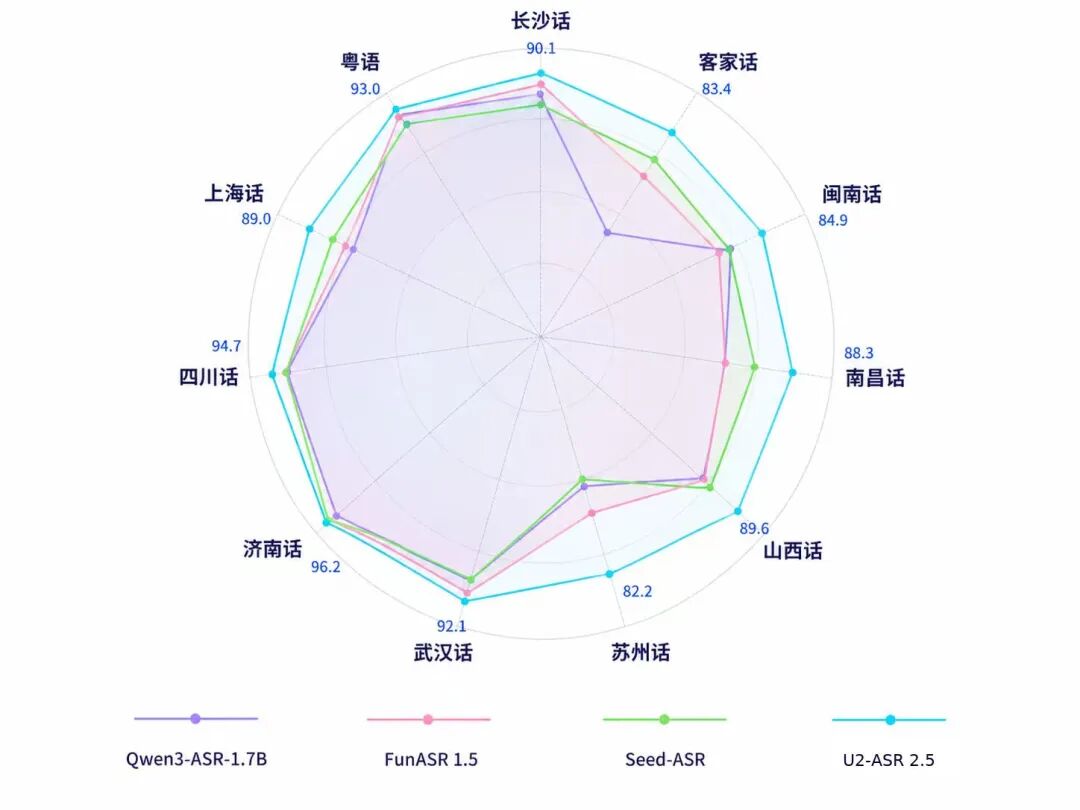
云知声推出的U2-ASR 2.5方言语音识别模型支持100种以上方言,识别准确率超过90%。该模型通过优化数据处理、解码和语义理解,将方言转化为规范普通话,广泛应用于政务、医疗和客服等领域。
关键要点
-
云知声推出的U2-ASR 2.5方言语音识别模型支持100种以上方言,识别准确率超过90%。
-
该模型通过优化数据处理、解码和语义理解,将方言转化为规范普通话。
-
U2-ASR 2.5在自有工业级方言测试集上,识别效果超越主流ASR模型,部分方言识别准确率突破90%。
-
模型在中英文识别任务中表现优异,进一步拓展了方言识别能力。
-
U2-ASR 2.5通过数据治理、解码优化和语义理解能力的提升,解决了方言识别的复杂性。
-
模型在高噪声环境中保持稳定识别能力,适用于医疗、政务和客服等多个场景。
-
U2-ASR 2.5支持热词动态注入,增强专业场景的识别能力,提升服务效率。
-
该模型的应用场景包括智慧政务、智慧医疗、智慧金融保险、智慧客服和文旅内容创作等。
延伸解读
方言识别的技术挑战
方言识别的复杂性源于其非标准化的特性。不同地区的方言在发音、用词和语境上存在显著差异,U2-ASR 2.5通过优化数据处理和解码技术,提升了对这些复杂表达的理解能力。这一技术突破使得模型在多样化的方言环境中表现出色,能够有效应对真实场景中的挑战。
应用场景的广泛性
U2-ASR 2.5的应用场景涵盖政务、医疗、客服等多个领域,能够有效提升服务效率和用户体验。在这些场景中,方言的使用频率较高,模型的准确识别能力能够减少沟通成本,促进信息的顺畅传递,尤其是在基层服务和医疗问诊中,显著提高了信息记录的准确性。
高噪声环境下的稳定性
U2-ASR 2.5在高噪声环境中的表现尤为突出,能够在复杂的背景音中保持稳定的识别能力。这一特性使得模型适用于如医院候诊区和夜市等嘈杂场所,确保用户的语音信息能够被准确捕捉,降低了因环境干扰导致的识别错误。
延伸问答
U2-ASR 2.5支持多少种方言的识别?
U2-ASR 2.5支持100种以上方言及地方口音的识别转写。
U2-ASR 2.5的识别准确率是多少?
U2-ASR 2.5的识别准确率超过90%。
U2-ASR 2.5在高噪声环境中的表现如何?
U2-ASR 2.5在高噪声环境中保持稳定的识别能力。
U2-ASR 2.5如何处理方言的复杂性?
U2-ASR 2.5通过数据治理、解码优化和语义理解能力的提升,解决了方言识别的复杂性。
U2-ASR 2.5的应用场景有哪些?
U2-ASR 2.5的应用场景包括智慧政务、智慧医疗、智慧金融保险、智慧客服和文旅内容创作等。
U2-ASR 2.5如何增强专业场景的识别能力?
U2-ASR 2.5支持热词动态注入,增强专业场景的识别能力,提升服务效率。
