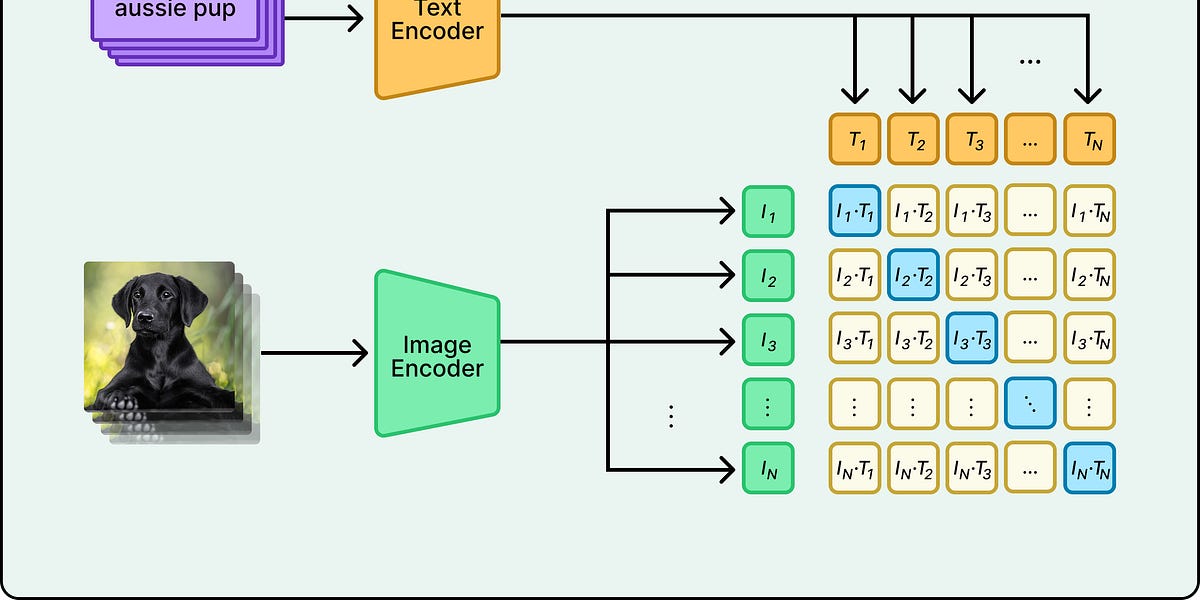
CLIP是OpenAI开发的神经网络,通过学习4亿对图像和文本,实现无标注数据的图像分类。它通过匹配图像与文本描述,克服了传统计算机视觉的局限性,具有灵活性和高效性,广泛应用于AI领域。
本研究提出了一种无须标注数据的偏差发现框架C2B,旨在克服传统偏差识别方法的局限性。C2B通过文本描述生成偏差提议,并评估分类模型的偏差准确性,实验结果表明其性能优于现有方法,具有广泛的应用潜力。
Databricks推出的TAO方法能够在无标注数据的情况下微调大型语言模型(LLMs),其性能超越传统方法。TAO通过测试时计算和强化学习提升模型质量,降低企业成本。实验表明,TAO显著提升了Llama模型在企业任务中的表现,达到了商业模型水平。
吴恩达推出Agentic Object Detection技术,该AI模型能够在无标注数据的情况下识别图片中的物体,实现零样本标记。用户可免费体验,尽管存在识别误差,但未来应用潜力巨大。
本文探讨了利用无标注文本数据提升生物医学命名实体识别(NER)模型性能的方法,包括双向语言模型(BiLM)、条件随机场和负采样等技术。这些方法显著提高了模型的准确性和训练效率,尤其在处理弱类和少样本数据时表现优异。
该文章探讨了人脸验证中的协变量影响及如何利用性别信息提升性能。研究表明,无标注数据可有效替代有标注数据,采用CDP方法在MegaFace挑战中取得78.18%准确率。此外,提出了对抗性人脸生成方法及FACESEC框架,评估人脸识别系统的鲁棒性,发现神经网络结构的准确性更为重要。通过自我监督学习和对抗攻击方法,提升了人脸识别的精度和安全性。
本文提出多种方法提升机器人操作能力,包括无标注数据训练、深度学习和自然语言指令。研究表明,利用少量专家演示和文本引导扩充数据,机器人在新场景中表现优异,具备自主学习和适应新任务的能力。
本研究探讨了对比学习在语义分割中的应用,提出了视频级对比学习、像素级度量学习和空间-时间同步对比学习等方法,以提升模型性能。实验结果显示,这些方法在动作分类、视频检索和3D点云分割等任务中显著改善,尤其在无标注数据和复杂场景处理上表现优越。
本文探讨了利用自监督方法和无标注数据构建伪训练数据,以解决训练数据短缺的问题。研究表明,该方法在英语Switchboard数据集上表现优异,误差降低21%。提出的LARD方法有效生成人工语言障碍,提升混淆检测器的准确性。研究还分析了大型语言模型在数据增强和反事实生成中的应用潜力,强调了准确任务定义的重要性。
本文介绍了一种语义对比学习的方法(SCL),通过引入距离的聚类结构到无标注数据的特征空间中,推理出语义上的实体类别。实验证明,SCL 在物体识别基准测试中优于其他方法。
完成下面两步后,将自动完成登录并继续当前操作。