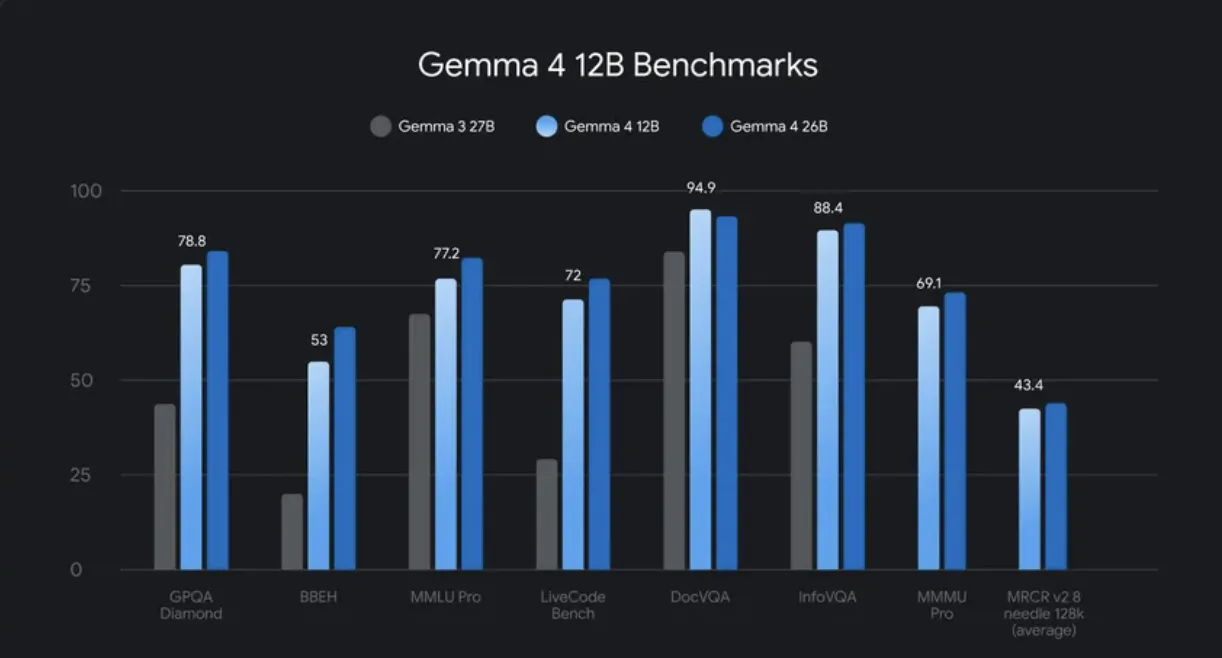
Google DeepMind 发布了 Gemma 4 12B,这是一个无编码器的多模态模型,支持文本、图像、音频和视频处理。该模型在消费级笔记本电脑上运行,性能接近 26B MoE 模型,但内存占用不到一半。它通过直接输入视觉和音频数据,简化了处理流程,提升了整体质量和指令遵循性。
本研究提出了一种名为BREEN的无编码器多模态学习架构,旨在减少训练数据需求。BREEN通过可学习查询和图像专家提高了性能,为传统编码器方法提供了有效的替代方案。
本研究提出了一种新型无编码器多模态大语言模型SynerGen-VL,采用令牌折叠机制和视觉专家的预训练策略,简化了模型架构和训练流程,支持高分辨率图像理解。经过训练,SynerGen-VL的性能与现有模型相当或更佳,展现了统一多模态模型的潜力。
智源研究院与大连理工大学、北京大学等合作推出了新一代无编码器的视觉语言模型EVE。EVE通过去除视觉编码器,能处理任意图像长宽比,并通过精细化的训练策略和额外的视觉监督,在多个视觉-语言基准测试中表现出色,与基于编码器的主流多模态方法相媲美。EVE的提出为纯解码器的原生多模态架构发展提供了一条透明且高效的路径。
完成下面两步后,将自动完成登录并继续当前操作。