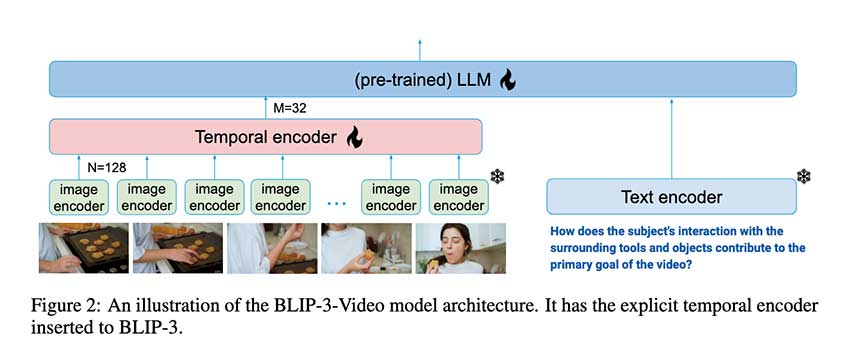
视觉语言模型(VLM)在视频理解中变得越来越重要,特别是BLIP-3-Video模型通过引入时间编码器显著提升了视频处理效率。该模型将视觉标记数量减少至16-32个,保持高准确率并降低计算开销,适用于复杂视频任务,推动了AI在各行业的应用。
完成下面两步后,将自动完成登录并继续当前操作。