
Salesforce AI Research 推出 BLIP-3-Video:用于视频的多模态语言模型,旨在有效捕捉多帧的时间信息
原文中文,约2000字,阅读约需5分钟。
📝
内容提要
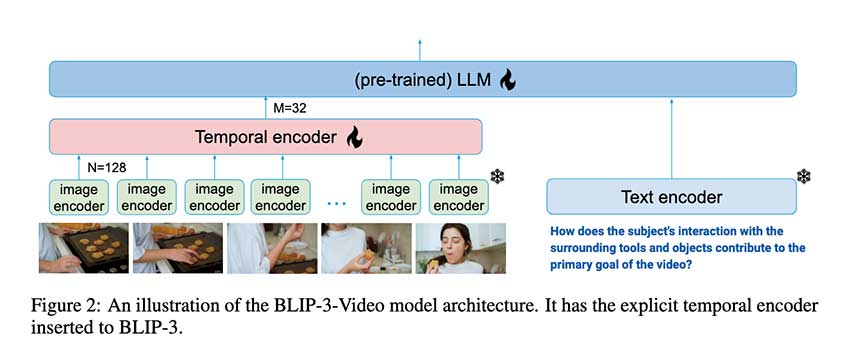
视觉语言模型(VLM)在视频理解中变得越来越重要,特别是BLIP-3-Video模型通过引入时间编码器显著提升了视频处理效率。该模型将视觉标记数量减少至16-32个,保持高准确率并降低计算开销,适用于复杂视频任务,推动了AI在各行业的应用。
🎯
关键要点
-
视觉语言模型(VLM)在视频理解中越来越重要,尤其是BLIP-3-Video模型。
-
BLIP-3-Video通过引入时间编码器显著提升视频处理效率。
-
该模型将视觉标记数量减少至16-32个,保持高准确率并降低计算开销。
-
BLIP-3-Video适用于复杂视频任务,推动了AI在各行业的应用。
-
现有模型通常依赖单独处理每个视频帧,导致计算资源消耗大。
-
BLIP-3-Video采用可学习的时空注意力池机制,提取最具信息量的标记。
-
该模型在多个基准测试中表现优异,保持高准确率。
-
BLIP-3-Video是目前最高效的标记效率模型之一,降低计算开销同时保持性能。
-
这一进步为视频理解任务提供了更具可扩展性和效率的解决方案。
❓
延伸问答
BLIP-3-Video模型的主要创新是什么?
BLIP-3-Video模型通过引入时间编码器,显著提高了视频处理效率,减少了所需的视觉标记数量。
BLIP-3-Video模型如何提高视频处理效率?
该模型将视觉标记数量减少至16-32个,并采用可学习的时空注意力池机制,提取最具信息量的标记。
BLIP-3-Video在视频问答任务中的表现如何?
BLIP-3-Video在MSVD-QA基准上获得77.7%的分数,在MSRVTT-QA基准上获得60.0%的分数,表现优异。
BLIP-3-Video模型的计算开销如何?
该模型在保持高准确率的同时,显著降低了计算开销,是目前最高效的标记效率模型之一。
BLIP-3-Video模型适用于哪些应用场景?
该模型适用于复杂视频任务,如视频理解、人机交互和多媒体应用等。
BLIP-3-Video与其他模型相比有什么优势?
BLIP-3-Video在使用更少的视觉标记时,仍能保持与大型模型相当的准确率,效率更高。
🏷️
