
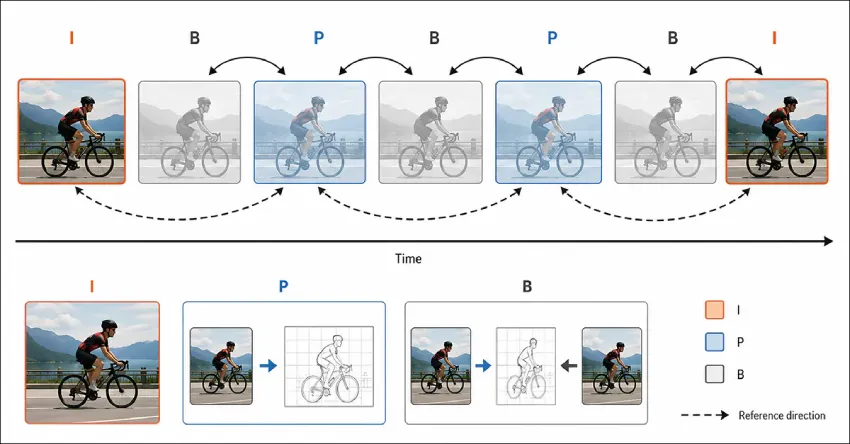

TrajTok:学习轨迹标记以提升视频理解
Apple Machine Learning Research
·

飞桨星河社区月度报告(2026年1月)
百度大脑
·
自托管在线文件转换器,千种格式轻松转换 | 开源日报 No.852
开源服务指南
·

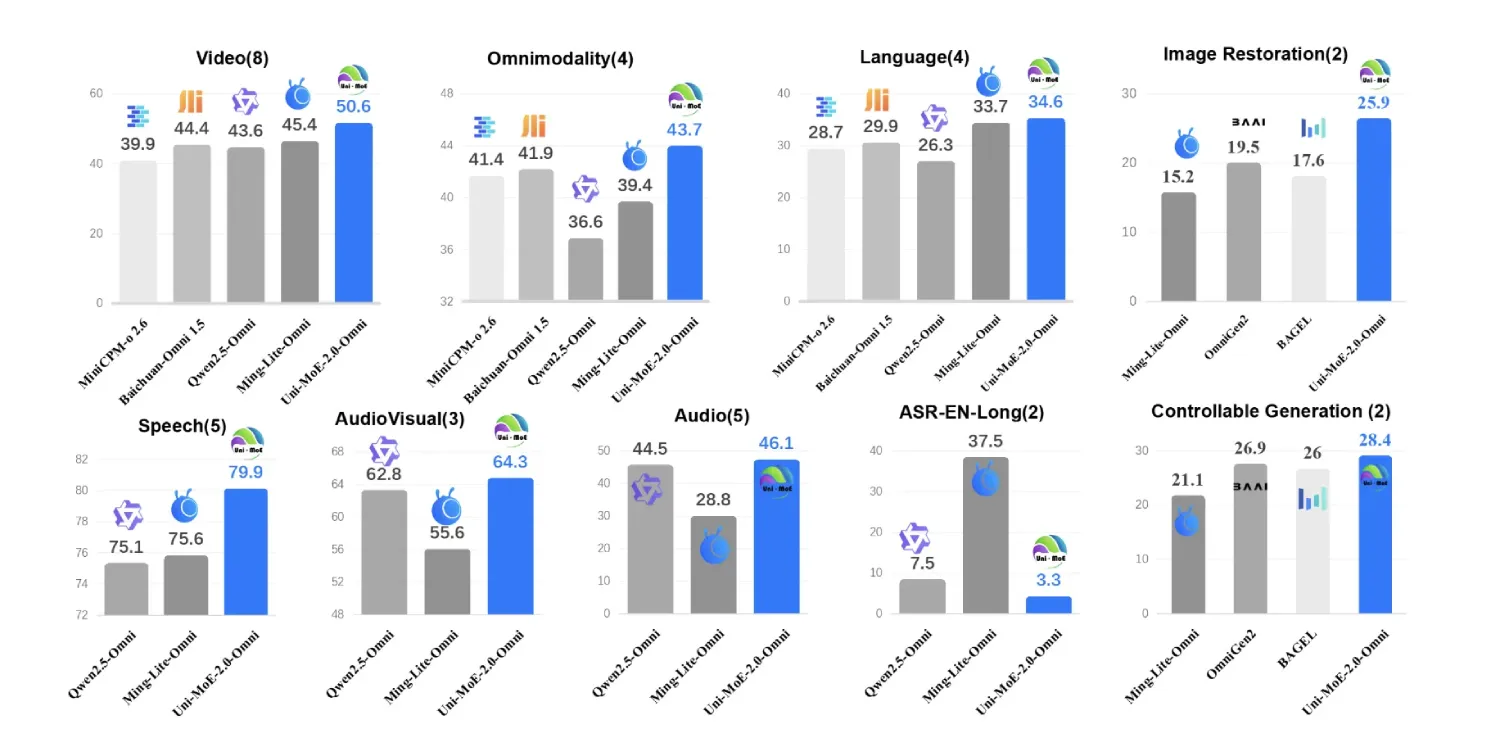
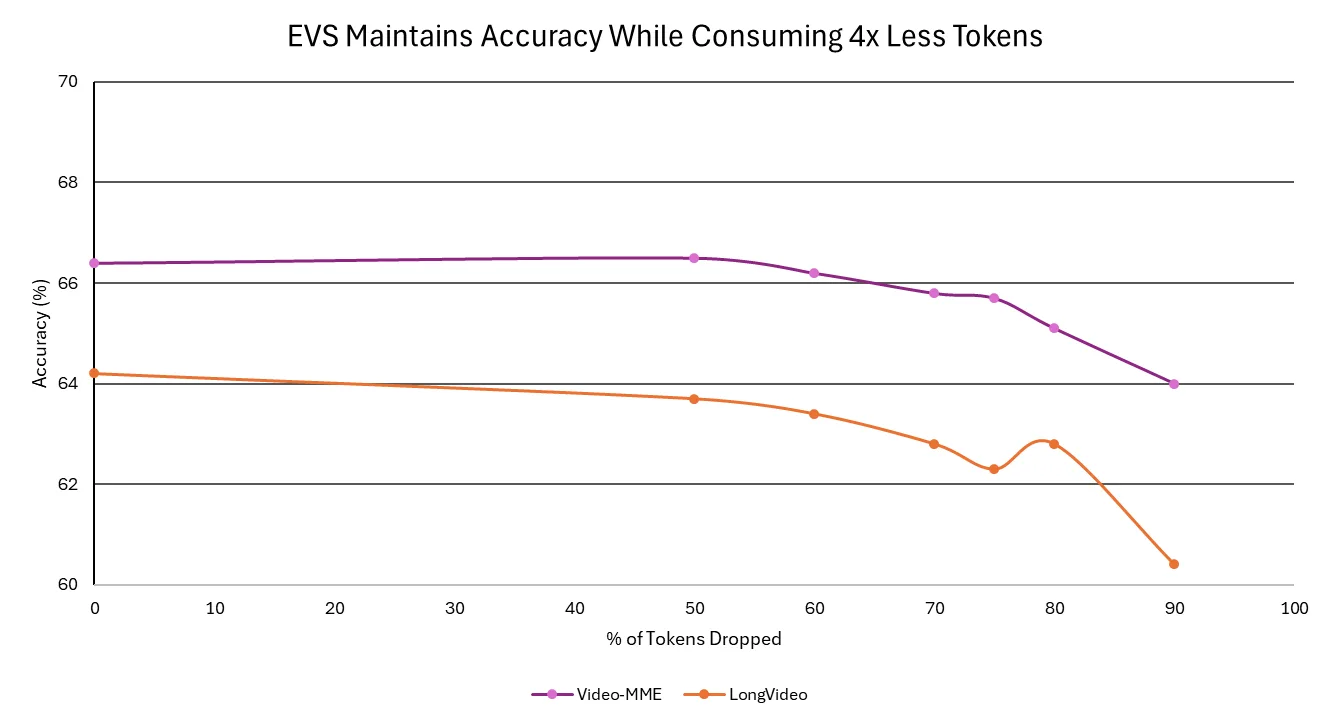
在vLLM上运行NVIDIA Nemotron的多模态推理代理
vLLM Blog
·

剖析视频大语言模型基准:知识、空间感知还是真实的时间理解?
Apple Machine Learning Research
·

ICCV 2025 | 美团论文精选及多模态推理竞赛冠军方法分享
美团技术团队
·
SlowFast-LLaVA-1.5:一种高效的长视频理解视频大语言模型家族
Apple Machine Learning Research
·

TwelveLabs 视频理解模型现已在 Amazon Bedrock 中推出
亚马逊AWS官方博客
·

