
Uni-MoE-2.0-Omni:基于开源Qwen2.5-7B的文本、图像、音频与视频理解全模态MoE模型
内容提要
Uni-MoE-2.0-Omni是哈尔滨工业大学深圳分校研发的全模态大型模型,支持文本、图像、音频和视频的理解与生成。基于Qwen2.5-7B模型,采用动态容量路由和渐进式监督学习,显著提升了跨模态推理能力,尤其在视频理解和长语音处理方面表现优异。
关键要点
-
Uni-MoE-2.0-Omni是哈尔滨工业大学深圳分校研发的全模态大型模型,支持文本、图像、音频和视频的理解与生成。
-
该模型基于Qwen2.5-7B模型,采用动态容量路由和渐进式监督学习,显著提升了跨模态推理能力。
-
Uni-MoE-2.0-Omni的核心是一个Qwen2.5-7B风格的Transformer模型,集成了统一的语音编码器和预训练的视觉编码器。
-
该系统支持10种跨模态输入配置,能够处理文本、图像、音频和视频的理解任务,并生成相应内容。
-
全模态3D RoPE机制将时间和空间结构编码到旋转位置嵌入中,增强了模型对标记时间和位置的理解。
-
混合专家模型(MoE)通过路由网络选择激活专家,实现专业化而不增加计算成本。
-
训练方案包括跨模态预训练、渐进式监督微调和基于GSPO和DPO的强化学习,以提高模型的推理能力。
-
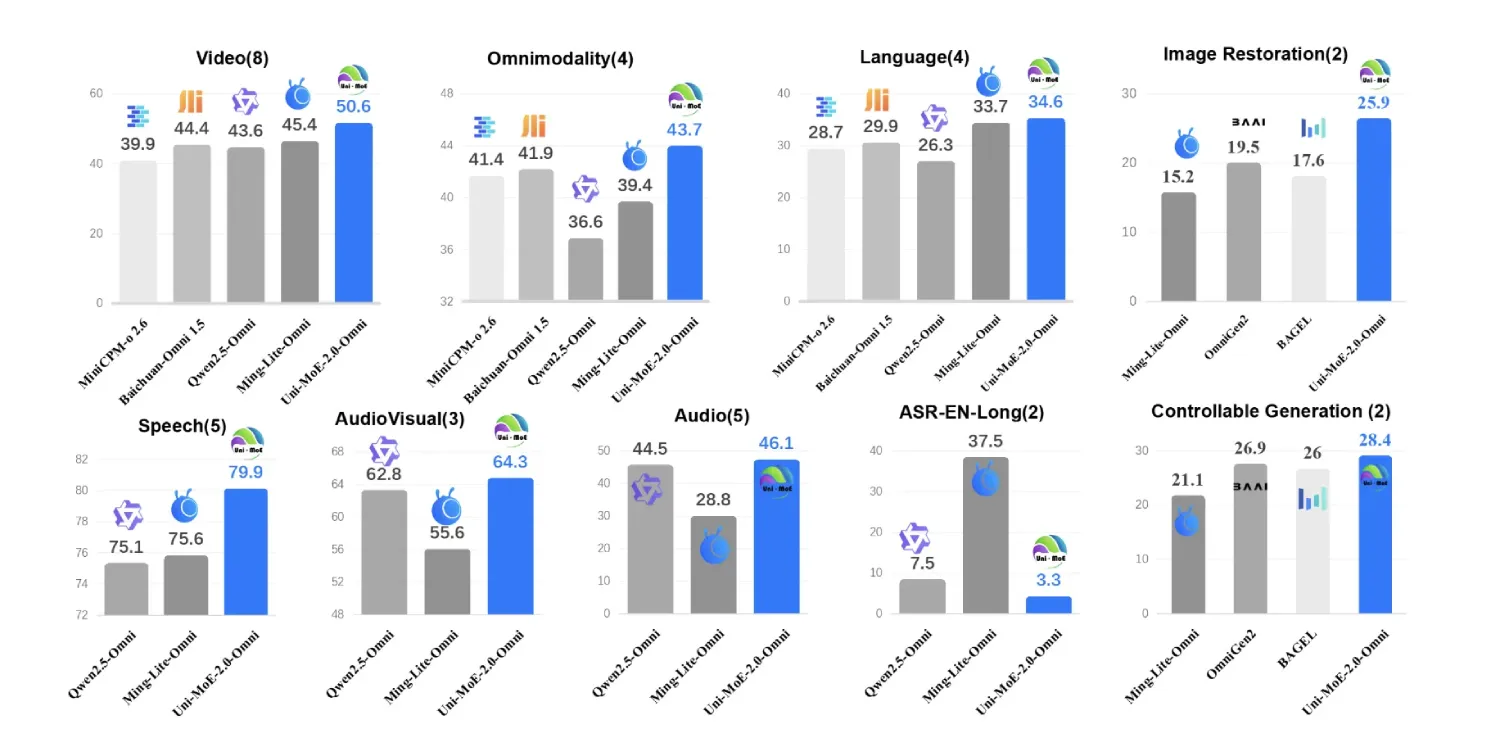
Uni-MoE-2.0-Omni在85项多模态基准测试中表现优异,尤其在视频理解和长语音处理方面有显著提升。
-
该模型在视频理解任务中平均性能提升约7%,在长篇语音处理中的词错误率降低高达4.2%。
延伸解读
全模态模型的优势
Uni-MoE-2.0-Omni作为全模态大型模型,能够同时处理文本、图像、音频和视频,展现出强大的跨模态推理能力。这种能力使得它在多种应用场景中具有广泛的适用性,例如在教育、娱乐和医疗等领域,能够提供更为丰富和直观的用户体验。
动态容量路由的创新
该模型采用动态容量路由和混合专家架构,能够根据输入的不同选择激活相应的专家。这种设计不仅提高了模型的专业化能力,还有效降低了计算成本,使得在处理复杂任务时更加高效。用户在选择模型时,可以关注其在特定任务上的表现,以获得最佳效果。
训练方法的多样性
Uni-MoE-2.0-Omni的训练方案包括跨模态预训练和渐进式监督微调,结合了GSPO和DPO的强化学习。这种多阶段的训练方法使得模型在长篇推理和复杂任务中表现出色,用户在应用时应注意模型的训练背景,以便更好地理解其能力和局限性。
延伸问答
Uni-MoE-2.0-Omni模型的主要功能是什么?
Uni-MoE-2.0-Omni模型支持文本、图像、音频和视频的理解与生成。
Uni-MoE-2.0-Omni是基于哪个模型开发的?
该模型基于Qwen2.5-7B模型开发。
Uni-MoE-2.0-Omni在视频理解方面的表现如何?
在视频理解任务中,Uni-MoE-2.0-Omni的平均性能提升约7%。
该模型采用了什么样的训练方案?
训练方案包括跨模态预训练、渐进式监督微调和基于GSPO和DPO的强化学习。
Uni-MoE-2.0-Omni如何处理不同模态的数据?
该系统支持10种跨模态输入配置,能够处理文本、图像、音频和视频的理解任务。
Uni-MoE-2.0-Omni在长篇语音处理中的表现如何?
在长篇语音处理任务中,词错误率降低高达4.2%。
