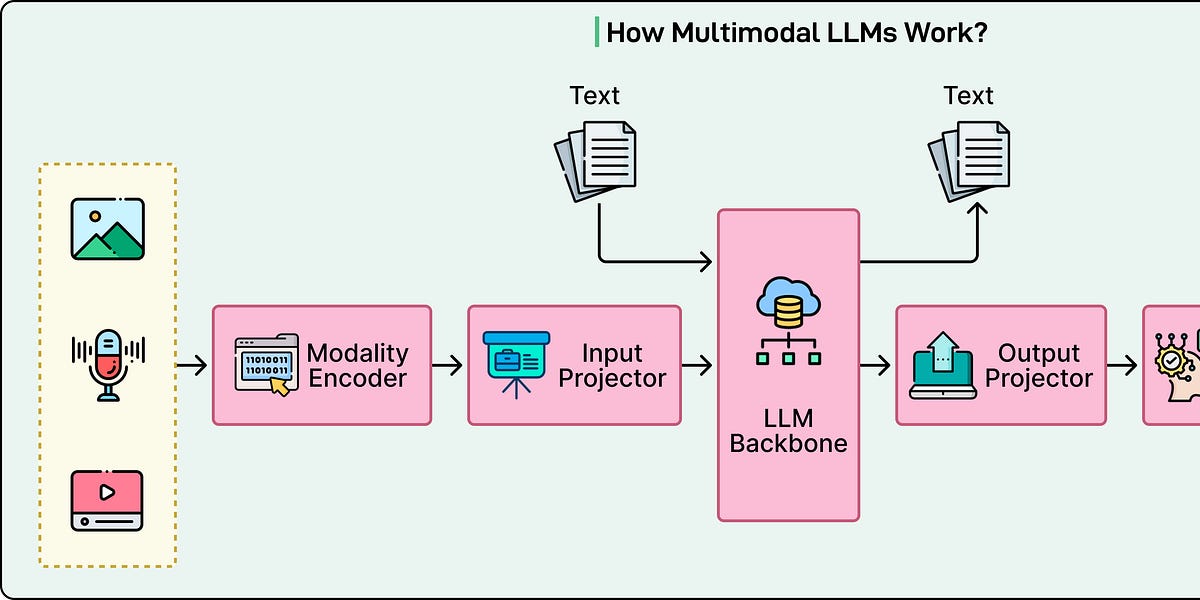
静态训练数据无法适应快速变化的信息,导致模型只能进行猜测。本文介绍了多模态大语言模型(LLM)的原理,通过将文本、图像和音频转化为统一的数学表示,模型实现了跨模态推理,能够实时理解和响应。
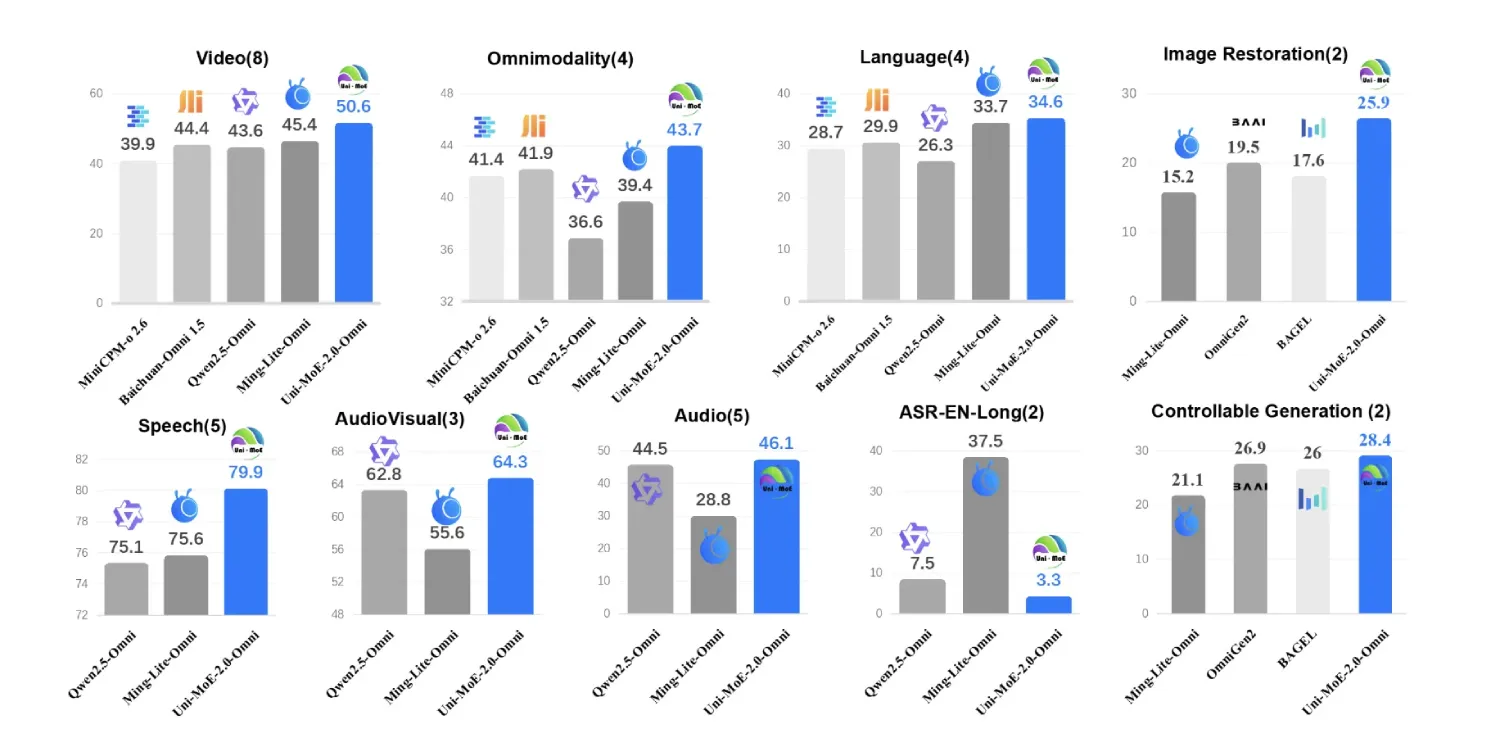
Uni-MoE-2.0-Omni是哈尔滨工业大学深圳分校研发的全模态大型模型,支持文本、图像、音频和视频的理解与生成。基于Qwen2.5-7B模型,采用动态容量路由和渐进式监督学习,显著提升了跨模态推理能力,尤其在视频理解和长语音处理方面表现优异。
百度于11月11日开源ERNIE-4.5-VL-28B-A3B-Thinking模型,具备3B激活参数,性能媲美顶级大模型。该模型在视觉语言理解、文档解析和跨模态推理方面表现优异,支持“图像思考”等创新功能,已在多个平台发布,适合商业使用。
快手开源了多模态推理模型Keye-VL 1.5,具备128k上下文、0.1秒视频定位和跨模态推理能力。该模型在视频理解和推理方面表现优异,能够准确判断物品出现的时间并详细描述场景,在多个基准测试中取得领先成绩。
字节Seed推出的M3-Agent多模态智能体具备长期记忆和实时感知能力,通过强化学习提升推理效果,优于现有模型。M3-Bench基准评估其在长视频理解中的表现,展现出卓越的跨模态推理能力。
多模态版DeepSeek-R1(Align-DS-V)由北大与港科大联合开发,超越GPT-4o,具备跨模态推理能力。通过Align-Anything框架,模型在视觉理解和文本推理上显著提升,复杂任务成绩从21.4提升至40.5。该框架支持多模态对齐,促进人工智能与人类意图结合,已开源并持续维护。
本文介绍了 TableVQA-Bench 基准,用于表格视觉问答,比较了多模态大型语言模型的性能,发现 GPT-4V 表现最佳。研究揭示了视觉输入处理的挑战,并提出了新的跨模态推理方法和框架 Solar,实验结果显示其在多个数据集上优于现有方法。
谷歌的PDF Gemini团队介绍了一种新的多模态模型系列Gemini,能够理解图像、音频、视频和文本。Gemini系列包括Ultra、Pro和Nano三种规模,适用于各种推理任务和内存受限的设备。Gemini Ultra模型在30个基准测试中有30个领先于现有技术水平,特别是在MMLU基准测试中达到了人类专家水平,并在20个多模态基准测试中改进了现有技术水平。Gemini模型在跨模态推理和语言理解方面的新能力将被广泛应用,并讨论了部署这些模型的方法。
完成下面两步后,将自动完成登录并继续当前操作。