本文探讨了通过学习长期运动嵌入来高效生成运动的技术。研究表明,利用大规模轨迹获得的运动嵌入,可以更有效地生成长时间的真实运动,以满足文本提示或空间指令的目标。通过压缩运动嵌入并训练条件流匹配模型,生成的运动分布优于现有视频模型和特定任务方法。
本研究提出了一种在线奖励加权条件流匹配方法,有效解决了持续流生成模型在对齐用户奖励时的政策崩溃和高计算成本问题,且在多个任务中表现优异。
本研究提出了VoicePrompter模型,解决了零-shot语音转换中说话人相似性不足的问题。该模型通过结合语音提示和条件流匹配,显著提升了转换的自然性和相似性,实验结果超越了现有系统,展现出重要的应用潜力。
本研究提出YingSound模型,解决产品视频生成音效时标记数据不足的问题。该模型通过条件流匹配变换器实现音频与视觉的语义对齐,并引入多模态思维链方法,实验结果表明其能有效生成高质量的同步音效。
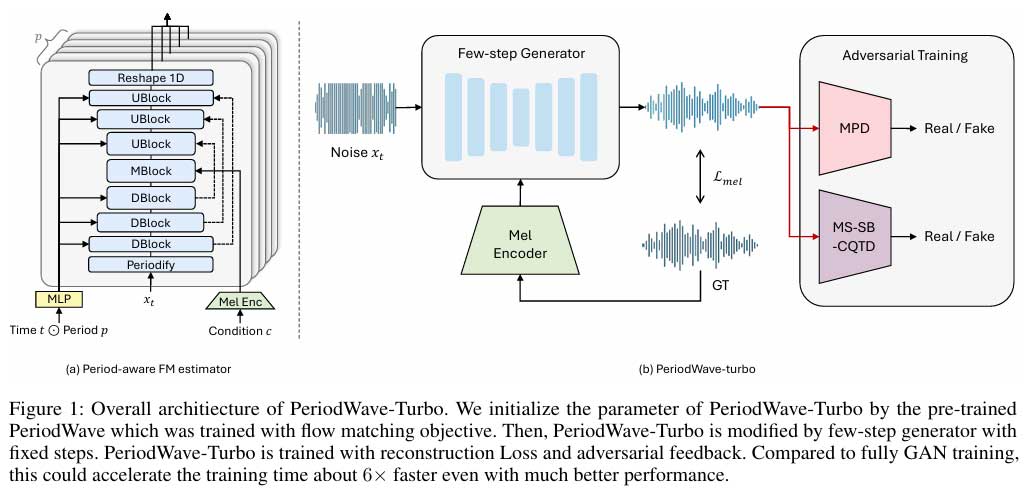
韩国研究人员开发了名为PeriodWave-Turbo的模型,旨在加快音频合成速度,保持音频质量。该模型通过简化步骤,减少了创建高保真音频所需的时间。使用预先训练的条件流匹配(CFM)模型和固定采样方法,只需2到4个步骤即可生成波形。PeriodWave-Turbo在LibriTTS数据集上获得高语音质量评估分数。通过加入重建损失和多周期多尺度判别器等技术,提高了音频质量和训练过程的稳定性。该模型为高保真波形生成提供了解决方案,并为实时音频应用带来了希望。
完成下面两步后,将自动完成登录并继续当前操作。