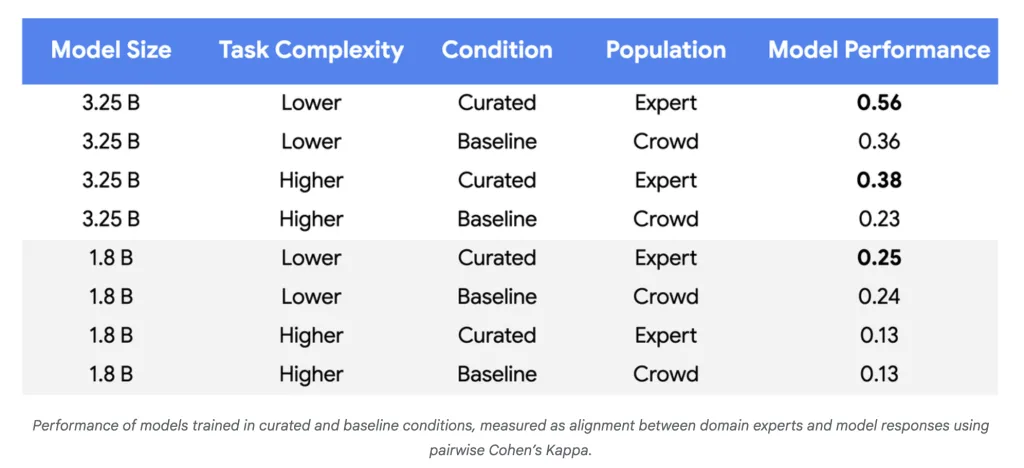
谷歌研究院推出了一种新方法,通过主动学习显著减少大语言模型微调所需的数据量,最多可减少10,000倍,同时提升模型质量。该方法专注于标注信息量最大的“边界案例”,提高了标签效率和模型适应性,降低了成本,加快了更新速度,并增强了处理敏感内容的能力。
完成下面两步后,将自动完成登录并继续当前操作。